[Windows] - char과 wchar_t의 차이점 (MBCS와 유니코드)
#. 일반 문자열과 L유니코드 문자열의 차이
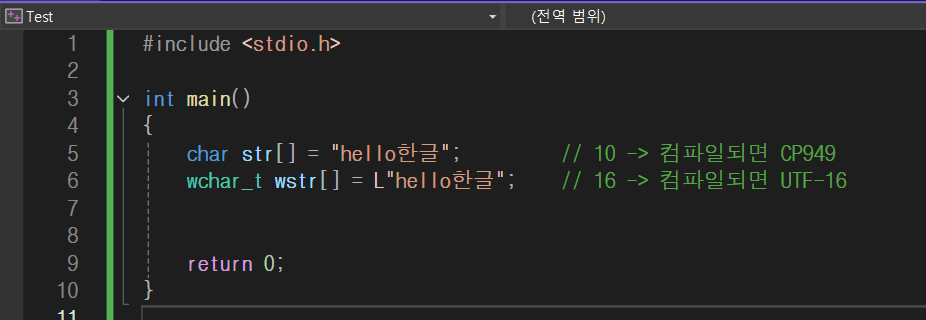
▷ 우선, 소스코드 자체는 UTF-8로 인코딩되었고, VC 컴파일러 옵션에도 소스코드가 UTF-8로 인코딩되었다고 설정했다. (설정 방법은 여기 링크)
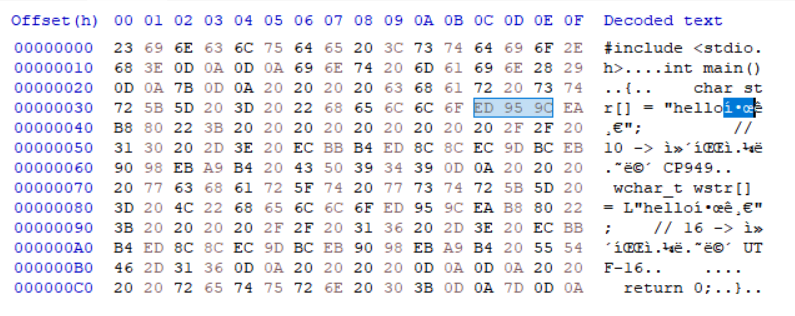
▷ 실제로 소스코드 텍스트 파일 자체의 바이너리 값을 보면 문자열도 UTF-8로 인코딩되어 있다는 것을 알 수 있다.
▷ 그러나 이건 어디까지나 텍스트 파일에 불과한 소스코드를 VC++ 컴파일러가 디코딩하는 차원의 문제이므로, 중요한 것은 빌드되고 난 뒤에 프로그램 내부에 문자열이 어떻게 인코딩되었는지 살펴보는 일이다.

▷ 빌드를 하고 난 뒤 윈도우 실행 파일(PE)의 내부 바이너리 데이터다. 문자열이 UTF-8이 아니라는 것을 쉽게 알 수 있다. 먼저, "hello한글"은 Windows의 로컬 환경인 CP949(MBCS)로 인코딩되어 저장되었다. 그리고 L"hello한글"은 UTF-16 유니코드로 인코딩되어 저장되었다.
▷ 그래서 각 문자열이 차지하는 데이터 크기는 먼저 "hello한글"이 10byte다. hello(5) + 한글(4) + null(1).
▷ L"hello한글"은 UTF-16이므로 문자 개수(4)에 곱하기 2를 한 값에 null(2)을 더해 16byte가 나온다.
# 결론!
▷ Windows에서는 평범하게 큰따옴표만 있는 "" 스타일(char타입)로 문자열을 작성하고 MSVC로 소스코드를 빌드하면 현재 Windows의 로컬 인코딩으로 문자열을 인코딩한다. 한국 Windows는 MBCS 기반인 CP949로 문자열이 인코딩된다.
▷ L"" 스타일의 문자열은 Windows에서 빌드 환경과 관련 없이 모두 UTF-16으로 인코딩한다. 즉, 모든 문자를 2바이트로 처리한다.
※ 참고) 리눅스에서 빌드하면 char 타입의 따옴표("") 문자열은 UTF-8, wchar_t 타입의 L"" 문자열은 UTF-32로 인코딩된다. UTF-32는 문자 하나를 4byte 고정값으로 쓰는 문자열로, 리눅스 계열에서 개발하는 사람들이 그 존재도 모를 정도로 쓰이지 않는 타입이다. 즉, 리눅스에서는 사실상 char 타입이 문자열 타입이다.
# 왜 플랫폼마다 해석이 다른가?
▷ char, wchar_t 모두 C표준이지만, 표준이라고 해서 그것을 어떻게 인코딩할 것인지는 명시하는 건 아니다.
▷ 그래서 각 플랫폼의 설계자들은 아주 중요한 C언어의 표준 문자 타입을 자체적으로 해석하려고 했다. 윈도우즈는 각국의 플랫폼의 MBCS가 OS의 기본 인코딩 설정이고, 시스템 내부적으로 문자열의 처리는 UTF-16을 선택했으므로 이에 따라 컴파일러(MSVC)를 설계한 것이다.
#4. 두 문자열 중 어떤 것을 사용해야 하는가?
▷ 이 결과로 알아야 할 사실은, 내가 char와 "" 문자열로 소스코드를 만들고 이것을 Windows MSVC로 빌드한 결과물은 배포해봤자 똑같은 CP949 기반의 한글 windows에서만 정상적인 동작을 보장할 수 있다는 것이다. 이것이 MBCS 인코딩의 아주 심각한 문제점이다.
▷ 예를 들어, 문자열을 가지고 처리하는 함수들을 묶어 라이브러리로 배포했다고 가정하자. 그러면 과연 내가 만은 이 라이브러리를 전 세계의 Windows 개발자들이 쉽게 사용할 수 있을까? 문자열을 CP949라고 가정하고 빌드한 이 함수들을...?
▷ 프로그래밍에서 문자열을 다루지 않을 수도 없는 노릇이다. 따라서 Windows에서 동작하는 프로그램이나 라이브러리 모듈을 개발하고 있고, 각 사용자의 Windows 환경과 상관 없이 일관된 동작을 하도록 만들고 싶다면, 모든 Windows에서 똑같이 동작하는 유니코드 기반의 wchar_t 타입과 L문자열을 사용해야 한다.
▷ 이렇게 유니코드 기반의 문자열과 Windows API를 사용하는 것이 성능에도 좋다. 애시당초 Windows API는 이미 예전부터 유니코드 UTF-16으로 커널과 시스템 API가 동작했으며, printf()와 같이 char 기반의 레거시 표준 라이브러리 코드도 내부적으로 MBCS -> Unicode(UTF-16)으로 변환되는 로직이 있으므로 성능이 약간 불리하다. Windows API를 char 기반으로 처리할 수도 있고, Windows가 그걸 지원해주기도 하지만 Windows API를 사용할 정도의 프로젝트에서 굳이 그런 식으로 번거롭게 개발할 이유가 없다.
▷ 게다가 평생 한국에서만 동작하는 소프트웨어만을 개발하고 배포할 것도 아니고, 그냥 처음부터 전 세계의 모든 문자열을 처리할 수 있도록 프로그램이나 라이브러리를 개발하는 것이 낫다. char와 "" 같은 레거시 기반의 소스코드를 만들어 빌드하고 배포하면 나중에 혹시나 다국어 지원이 필요하거나 전 세계에 배포할 때, 고리타분하게 char를 쓴 과거의 자신을 후회하지 않을까?