프레임워크와 라이브러리는 모두 모듈로서 제공된다. 그래서 표면적으로는 아무런 차이가 없는 것 같다. 하지만 서로 다르다.
개발자가 작성한 코드는 프레임워크가 호출한다. 반대로 라이브러리는 개발자가 작성한 코드가 호출한다. 그러나 더욱 심도 깊게 들어가면 본질적인 차이가 하나 있다.
그것은 바로 "의존성 역전(Dependancy Inversion)" 원리다.
1. 의존성 역전 (제어 역전)
의존성 역전에서 중요한 단어는 '역전'되었다는 표현이라고 나는 생각한다. 물론 내용적 측면을 다루는 단어는 "의존성" 이다. 하지만 DI는 "역전"되었다는 사실을 더욱 강조한 표현이다.
역전이라는 표현은 제어흐름과 소스코드 의존 방향에 대한 전통적인 관점을 역전시켰다는 의미로서의 역전이다. 따라서 역전이라는 단어를 이해하기 위한 출발점은 먼저 전통적인 코딩 패러다임을 이해하는 것이다.
1-1. 절차적 프로그래밍
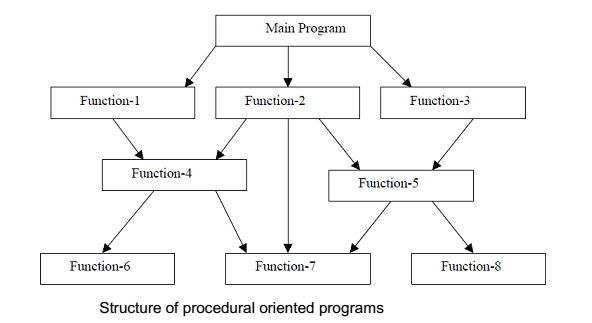
전통적인 코딩 패러다임은 프로시저 지향 프로그래밍(절차적 프로그래밍)이고, 위 그림과 같은 Top-Down 구조를 취한다.
main 함수로부터 시작해 기능을 추상적으로 분해해나간다. main 알고리즘은 제어가 흘러가면서 하위 함수를 호출해나가고, 다시 이런 구조가 재귀적으로 이어진다. 전통적인 패러다임 하에서는 main 함수를 기준으로 function에 대한 트리 구조를 그릴 수 있다.
여기서 중요한 핵심 두 가지는 제어 흐름과 소스코드 의존이다. main 알고리즘이 명령을 순차적으로 실행해나가다 function 호출 문법을 만나게 되면 그것을 호출한다. 그리고 제어 흐름이 해당 function으로 넘어간다.
이 패러다임에서는 소스코드의 의존성의 방향과 제어 흐름은 동일하다. 의존성이란 복잡하게 생각할 필요 없이 말 그대로 누가 누구를 사용하는지 판단하면 된다. main 상위 함수가 하위 함수를 사용한다. 그렇게 하위 함수에 의존한다. 따라서 의존되는 하위 함수가 변경되면 상위 함수는 직접적으로 영향을 받는다.
사실 처음 main 함수를 만들며 기능을 분해해나갈 때는 이러한 변경의 위험이 감지되지 않는다. 알고리즘도 간단하고 Top-Down 방식의 기능 분해는 컴퓨팅 사고력의 근간이므로 많은 개발자들이 직관적으로 익히는 코드 설계 기술이기 때문이다.
그러나 진짜 위기는 해당 알고리즘을 가지고 여러 번의 수정과 변경이 가해질 때다. 원래의 알고리즘을 토대로 분해된 기능들은 새로운 요구 및 변경 사항에 대해 속절없이 무너지기 마련이다. 특히 하위 함수에서 발생한 문제점은 그대로 상위 함수의 문제로 직결되고, 이는 다시 function 트리의 모든 함수에 영향을 미칠 수 있다.
1-2. 객체지향 프로그래밍
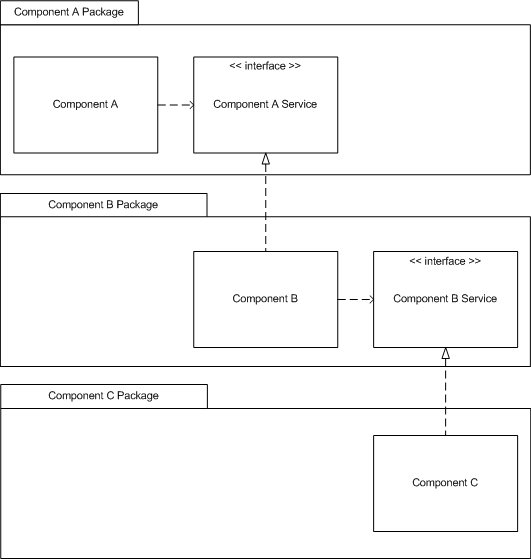
그런데 객체지향에서는 소스코드 의존성이 역전된다.
런타임에서 제어 흐름은 절차적 프로그래밍 방식과 크게 다를 것이 없다. 객체 A가 인터페이스든 추상클래스든 구체적인 클래스든 상관 없이, 다른 객체의 메소드를 호출하면 특정 객체의 메소드가 호출되어 실행된다. 코드의 제어 흐름은 호출된 객체에게 넘어간다.
그런데 여기서 재밌는 점은 소스코드의 의존성은 반대라는 것이다. 위 그림에서 컴포넌트A는 service라는 어떤 역할에게 메시지를 전송하고 있다. 이것은 추상화된 역할이라는 점이 중요하다. (추상화된 역할은 인터페이스나 추상클래스로 구현된다.)
컴포넌트A는 적절한 역할을 수행하는 객체가 런타임에 선택될 것이라고 믿고, 인터페이스를 통해 메시지를 보낼 수 있다고 가정한다. 이를 토대로 철저하게 자신의 로직에만 집중한다. 즉, 컴포넌트 A는 그 어떤 하위 모듈에도 의존하지 않는다.
오히려 소스코드에 의존하는 것은 하위 모듈인 컴포넌트B다. 인터페이스 계약을 지켜야 하는 입장은 컴포넌트B이다. 소스코드의 의존 방향이 이렇게 역전된다.
2. 의존성 역전을 통해 협력을 추상화하다 : 프레임워크
단순히 DI를 활용했답시고 프레임워크라고 불러서는 안 된다. DI는 DI일 뿐이다. DI를 썼다고 프레임워크라고 해서는 안 된다.
프레임워크는 그저 단순히 의존성 역전(DI)을 사용한 것이 아니다. 의존성 역전 원칙을 활용해 상위 모듈을 추상화하여 협력 구조를 설계하고 로직을 구현한 것이다. 프레임워크는 시스템 전체 있어 어떤 고정적인 설계, 추상화/일반화된 논리를 담는 상위 모듈이다.
프레임워크의 강점은 실제로 구현된 코드가 담겨 있다는 점이다. 어떻게 협력해야 하는지 이미 프레임워크가 그 구조와 함께 내용도 전부 설계하고, 또 상위 모듈의 로직에 대한 구현을 완료한 것이다. 프레임워크를 사용하는 개발자는 그저 프레임워크가 구체적인 내용으로서 비워놓은 부분(hook)을 채우면 된다.
프레임워크의 핵심은 협력의 추상화다.
프레임워크가 항상 정답인 것은 아니다. 메인 로직이 이미 구현되어 일반적으로 발생하는 기술적 문제를 대부분 해결한 것이기 때문에, 무언가를 개발해야 하는 입장에서 컨트롤할 수 있는 것이 그다지 많지 않다. 오직 프레임워크가 훅(hook)으로서 비워놓은 부분만을 채울 수 있을 뿐이다. 설령 어떤 제어 흐름에 영향을 주는 변수를 조정할 수 있다고 해도 어디까지나 프레임워크가 허용하는 한계 내에서만 가능하다.
따라서 완전히 새로운 환경에서 프로그램을 작성해야 하는 경우, 즉 프레임워크가 해결한 일반적인 문제들과 협력 구조가 현재 프로젝트에 그다지 유용하지 않다면 굳이 프레임워크에게 메인 컨트롤을 제어할 권한을 줄 이유가 없다.
물론 프레임워크는 보통 어떤 개발에 있어 일반적인 기술적인 문제를 전부 자신이 해결하고 나머지 남은 부분 (비즈니스 로직) 만을 개발자에게 넘기기 때문에, 특별히 구체적으로 제어를 제어해야 하는 프로젝트가 아니라면 프레임워크는 굉장히 유용할 수 있다.
따라서 프레임워크는 일관된 협력이 필요한 경우, 그리고 특별히 세밀하게 제어 흐름을 스스로 구현해야 할 필요가 없는 경우, 빠르게 서비스를 개발해야 하는 경우 매우 유용하다.
그러나 프레임워크 자체의 안정성을 책임지고 프레임워크의 기능적 문제점을 해결하는 것은 전부 개발자의 몫이다. 또한 프레임워크를 사용할 경우 프레임워크가 허용하는 협력 방식을 이해해야 하기 때문에 학습에 대한 비용도 고려해야 한다.
이 때문에 함부로 최신 프레임워크를 마음껏 사용할 수 없는데, 이는 취업 시장에서 해당 최신 프레임워크에 대해 잘 아는 사람들을 빠르게 수급하기 힘들기 때문이다. 이것은 제어 흐름을 외부에 떠넘긴 만큼의 대가다.
라이브러리는 반대로 개발자가 라이브러리를 사용해 직접 제어 흐름을 코딩한다. 의존성의 방향은 역전되지 않는다. 제어 흐름이 호출하는 라이브러리에 의존한다. 전통적인 패러다임과 크게 다를 것이 없다. 따라서 라이브러리의 경우 너무 자주 명세가 바뀌는 라이브러리의 사용은 자제해야 한다.
'IT 공부 > 객체지향 설계 공부' 카테고리의 다른 글
| 동적 타입 언어와 정적 타입 언어의 차이점 (덕 타이핑) (0) | 2023.12.13 |
|---|---|
| 인터페이스 분리 원칙(ISP) 제대로 이해하기 (0) | 2023.12.11 |
| 추상 데이터 타입 vs 객체지향의 객체 (0) | 2023.12.08 |
| 훌륭한 인터페이스의 특징 (오브젝트 6장) (0) | 2023.12.08 |
| 객체지향 언어로 절차적 프로그래밍을 하는 문제 (0) | 2023.12.07 |



