1. 커널 쓰레드와 사용자 쓰레드 차이
과거 오래된 유닉스 시스템에서는 멀티쓰레드를 지원해주지 않았고 멀티프로세스만을 지원했다. 그러나 시간이 흘러 멀티쓰레드를 지원해주는 OS가 생겨나면서 커널이 쓰레드 단위를 인식하고 직접 관리나 스케쥴링을 해주는 서비스를 제공해줬다. 이것이 커널 쓰레드다.
물론 커널 쓰레드를 거치지 않고도 쓰레드 기능을 구현해볼 수는 있다. 이것이 사용자 쓰레드다. 하지만 사용자 쓰레드는 사용하는 프로그래밍 언어를 통해 직접 구현해보거나, 혹은 쓰레드를 관리해주는 라이브러리를 가져와 사용해야 한다.
현대 운영체제는 쓰레드와 프로세스를 모두 관리해주기 때문에 사용자 공간 자체에서 직접 쓰레드를 구현해 사용하는 경우는 없는 편이다. 게다가 사용자 쓰레드를 커널과 독립적으로 사용하는 경우는 다양한 문제에 직면할 수 있는데, 대부분의 원인은 커널이 오직 프로세스만을 인식할 뿐, 프로세스 내부의 쓰레드는 전혀 인식할 수 없다는 점에서 비롯되는 문제들이다.
예를 들어, 하나의 스레드에서 문제가 생기거나, 한 스레드가 시스템콜을 통해 IO 대기 상태에 들어가는 경우, 다른 쓰레드도 통째로 움직여 동시적으로 처리될 수 없다. 애초에 OS가 해당 프로세스를 하나의 독립적인 단위로 바라보기 때문이다. 즉, OS가 프로세스 내의 다양한 스레드를 인지하지 못한다고 봐야 한다.
물론 현대의 운영체제는 대부분 멀티 쓰레드를 지원해주며, 이는 리눅스나 macOS, windows의 API를 통해 지원해준다. 따라서 굳이 사용자 라이브러리를 가져오거나 직접 스레드 구현 및 스케쥴링 알고리즘을 구상할 필요는 없다. 사용하는 운영체제가 제공하는 라이브러리의 스레드 기능을 써서 커널이 관리하게 해주는 것이 편하다.
자바와 같은 가상 머신의 경우, 프로그래밍 언어에서 스레드 API를 사용하면 JVM이 내부적으로는 OS의 스레드 API를 사용하는 것으로 동작하기 때문에 사실상 커널 쓰레드를 사용하는 것이다.
2. 스케쥴링은 어떻게 하나
리눅스의 경우, 프로세스와 스레드를 엄밀히 구분하기보단 각각을 하나의 task로 인식한다. 쉽게 말해 스레드 단위로 스케쥴링을 한다. (프로세스간 스위칭도 스레드로 보는 것으로서 관점을 통일할 수 있다. 싱글 스레드 프로세스라면 하나의 스레드로 보면 되기 때문이다. 즉, 스레드가 없는 프로세스는 없다. 적어도 하나의 스레드를 가지고 있다.)
프로세스 내부에서 스레드 간 스위칭이 일어나는 것과 프로세스 간 스위칭이 일어나는 것 사이의 스케쥴링 알고리즘이 아주 다른 것은 아니고, 서로 비슷한 원리로 동작한다. 따라서 프로세스 대상의 스케쥴링 알고리즘을 공부하면 이미 충분히 공부한 것과 다름 없다.
프로세스가 스케쥴링될 때는 Process Control Block을 통해 스위칭을 지원한다. 이때 현대 OS는 여기서 끝내는 것이 아니라, PCB 내부에 TCB(Thread Control Block)을 가진다.
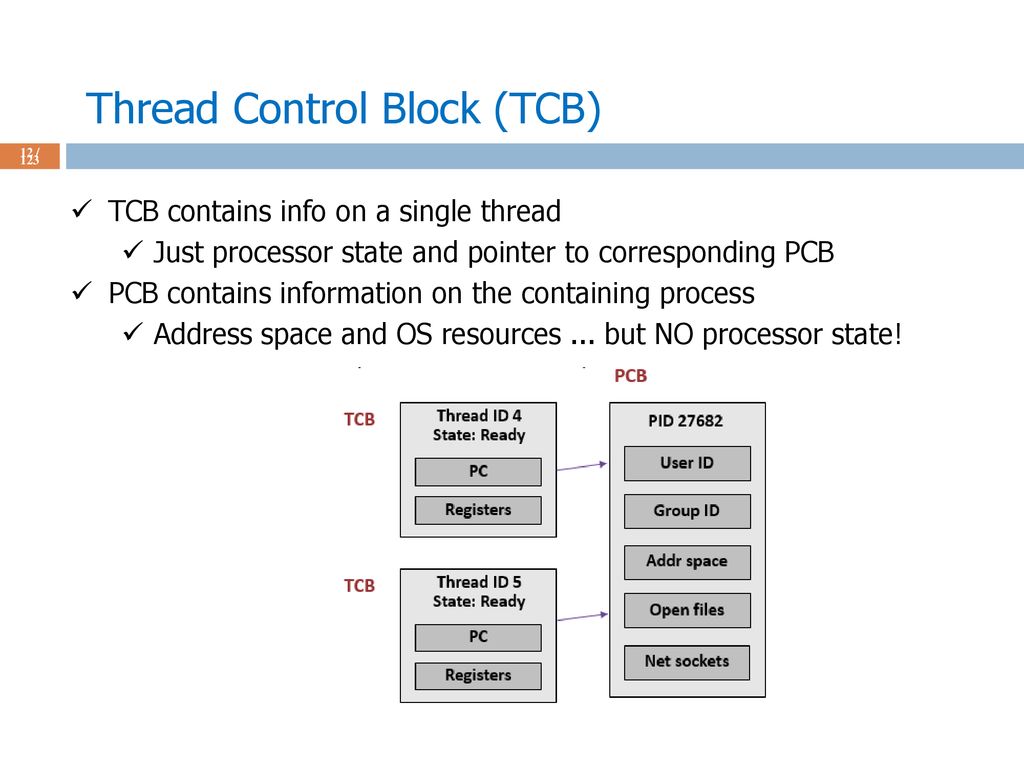
프로세스 내부의 스레드는 위 그림과 같이 PCB의 여러 내용들을 함께 공유하기 때문에 컨텍스트 스위칭이 프로세스 사이에서 일어나는 스위칭보다는 훨씬 더 빠르다.
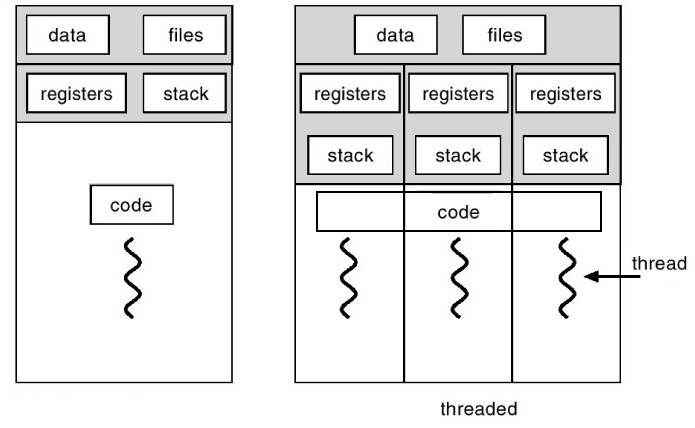
게다가 쓰레드는 위 그림과 같이, 메모리에서는 코드와 전역데이터, 힙을 공유한다. 이것은 메모리를 효율적으로 사용하는 것이다. 그런데 재밌는 점은 여기서 메모리 효율이 좋다는 것뿐만 아니라, 이러한 구조 덕분에 스위칭 효율도 함께 좋아진다는 것이다.
왜냐하면 데이터 공유 범위가 같다는 것은 즉, 캐시도 함께 공유할 수 있음을 뜻하기 때문이다. 그래서 프로세스간 스위칭보다 스레드간 스위칭이 더욱더 빠르다. (캐시 관련 속도 차이에 대해 알고 싶으면 여기!! → 링크)
물론 현대 컴퓨터는 스레드로 구성된 프로세스들이 함께 CPU와 RAM 등을 공유한다. 당연할 것이다. 스레드 단위로 스케쥴링을 한다고 해도 모든 프로그램을 스레드로 구성할 수는 없기 때문이다. 서로 완전히 다른 프로그램이라면 프로세스로 철저하게 구분된다.
따라서 스레드간 스위칭이 일어나면 빠르게 스위칭을 할 수는 있지만, 언젠가는 OS에 의해 프로세스 간 스위칭도 일어나야 한다. 이때는 어쩔 수 없이 컨텍스트 스위칭 비용을 감수해야 한다.
3. 자원의 할당과 제약 관련 프로세스, 스레드 차이
그러나 현대의 운영체제가 아무리 멀티쓰레딩을 지원해준다고 해도, 그리고 스레드를 독립적인 실행 흐름으로 인지해준다고 해도, 엄밀하게 보면 자원을 할당할 때는 프로세스와 스레드를 다르게 취급한다.
특히 메모리 자원이 그렇다. 프로그램이 정상 작동하기 위해 필요한 최소한의 전산 자원은 CPU와 RAM이다. 운영체제는 프로세스에게 CPU와 RAM을 할당한다. CPU 할당과 관련해서는 커널 내부의 스케쥴링 알고리즘을 따르고, 메모리와 관련해서는 가상메모리 등의 기법을 활용한다.
핵심은 메모리 할당이 오직 프로세스 단위로 제공된다는 점이다.
따라서 프로세스가 아무리 내부적으로 스레드를 많이 가져봤자 프로세스에게 제공된 메모리 자원 한계 내에서만 동작해야 한다.
스레드마다 각자 스택 자료구조를 가지고 있으나, 힙과 같은 자료구조는 공유한다. 이는 메모리 자원을 프로세스 단위로 제공되었기 때문에 가능한 것이다.
그러나 스택은 독자적으로 갖춰야 한다. 이는 스레드가 개별적인 실행 흐름(main이 독자적)을 가지고 있기 때문에 당연히 갖춰야 할 구조다. 이때 프로세스의 메모리 제약이 있기 때문에 여기서 도출할 수 있는 결론은, 쓰레드 생성은 결코 무한하지 않다는 점이다. 정확히 말하자면 스레드 개수의 가능성은 구체적으로 n개라고 결정되었다기보단, OS가 할당하는 프로세스의 스택 범위 안에서 결정난다.
'IT 공부 > 운영체제' 카테고리의 다른 글
| OS 배운거 정리 2024.10.29 - rex, 오퍼랜드 사이즈 접두사 개념 (0) | 2024.10.29 |
|---|---|
| [OS] - 프로세스와 스레드의 차이 (매우 중요) (0) | 2023.12.28 |
| [리눅스] - 인터프리터, 가상머신, 그리고 실행 파일의 명령어 구조 차이 (0) | 2023.12.18 |
| [리눅스] - 심볼릭 링크와 하드 링크 정리 및 사용 용례 (0) | 2023.12.18 |



