1. 개발에 있어서 컴퓨터 하드웨어 문제

컴퓨터 기계 장치의 하드웨어적인 본질은 무엇일까? 폰 노이만 아키텍처에 따르면, 컴퓨터의 기계적 본질은 프로세서인 CPU와, 데이터와 명령어가 저장된 스토리지인 RAM이다. RAM와 CPU 두 하드웨어만 있으면 그것이 곧 흠 잡을 데 없는 컴퓨터다. 튜링 기계와 등가다. 실제로 컴퓨터 장치를 공부할 때, NAND 게이트를 차곡차곡 조립해나가 8비트나 16비트 컴퓨터를 만들 때가 있는데, 이때도 간단한 CPU와 RAM만으로 컴퓨터를 완성할 수 있다. 이것만으로도 컴퓨터의 원리를 설명하는데 충분하기 때문이다.
그러나 컴퓨터는 기계 장치다. 물리적인 제약 조건에 강하게 결합되어 있다. 실제 컴퓨터는 구체적인 재료와 물리적인 비용을 바탕으로 설계된다. 즉, 그 속도와 명령 수행에 있어 한계가 있다는 것이다.
보통 이 한계를 인식하기가 쉽지 않다. 학부 전공생조차 이 한계를 바로바로 계산하기 어려워 한다고 들었다. 비전공자 늦깍이 취준생인 나는...? 말할 것도 없다. 사실 대부분의 사용자들은 컴퓨터의 물리적 한계를 체감하기가 쉽지 않다. 요즘 컴퓨터가 너무 발전하다보니 대부분의 소프트웨어는 즉각 즉각 실행된다. 만약 오류가 있다면 그것은 소프트웨어적인 버그라고 생각한다.

개발자가 아닌 사용자 입장에서 컴퓨터 하드웨어의 한계를 마주하는 경우는 그리 많지 않지만 어떤 상황에서는 자주 체감할 수 있다. 특히 게이머들이 그렇다. 최신 AAA 게임들은 하드웨어를 극한으로 사용하기 때문에 자주 하드웨어의 한계를 인식한다. 여담이지만 나는 겜트북으로 위쳐를 한 적이 있었는데, RT+ 울트라 같은 풀옵은 엄두도 못 낸다. 컴퓨터가 날 죽일 것이다.
사용자가 아닌 개발자로서 내가 처음으로 컴퓨터의 한계를 체감한 것은 C언어 자료구조 과제 중 캐시 히트율 계산하기 문제를 풀 때가 처음이었다. 조금 옛날이라 문제가 잘 기억나지 않지만, 대량의 데이터가 하나씩 입력될 때, 캐시 스토리지 안에 해당 데이터가 있으면 HIT이고, 없으면 MISS로 계산한 후 MISS가 뜬 데이터를 캐시에 넣어 스토리지를 갱신하는 문제였던 것으로 기억한다. HIT율을 개선하는 것까진 요구하지 않았다.
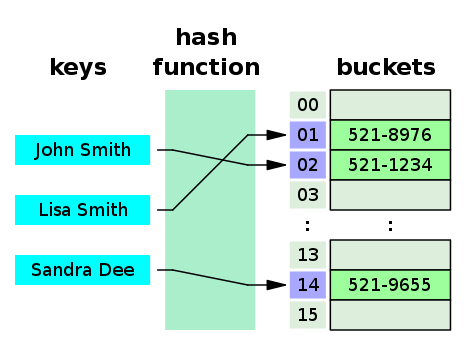
이때 내가 데이터 구조를 잘못 설계해 애를 먹었었다. 실수로 이진 트리로 캐시 스토리지를 구성했던 것이다. 알다시피 이진 트리는 검색이 쉽지 않다. 물론 복잡도는 logN으로 쓸만하지만, 데이터 용량이 클수록 분명 시간이 걸린다. HIT/MISS 계산할 때는 저장보다 검색이 매우 자주 발생한다. HIT이면 저장할 필요가 없기 때문이다. 검색에서의 시간 복잡도가 좋아야 하기 때문에 해시 테이블, 즉 랜덤 엑세스 방식으로 재설계했다. (이진 트리는 검색을 하려면 비교 연산을 계속 수행해야 하는 단점이 있다. 랜덤 엑세스가 아니다.)
이렇게 컴퓨팅 한계를 마주하고서야 비로소 아래와 같은 생각이 들었다.
컴퓨터가 한계가 있는 장치구나..
시간/공간 복잡도는 괜히 배우는게 아니구나..
2. 메모리 계층 구조와 컴퓨터의 한계
그러나 공부를 하면 할수록 컴퓨터의 공학적 관점에서의 한계에 대한 감각을 키우기가 참 쉽지 않다는 것을 느꼈다. 전공자와는 달리 내가 컴퓨터 하드웨어에 대한 공부를 따로 한 적이 없던 것도 있지만, 공학적 관점이란 것이 정말 말로 표현하기 힘든 어떤 감각과도 같은 것이라서 손에 잡히지 않는 느낌도 있어서 그렇다.
특히 아래의 문제는 참 충격이었다. 말 그대로, 컴퓨터의 공학적 한계에 대한 감각이 없으면 함정에 빠지는 문제다.
아주 큰 데이터의 비트열(0, 1, ...)에서 1의 개수를 효율적으로 구하는 방법은?
이진법의 원리를 사용해 데이터 N을 2로 나눠가며 나머지를 더하는 식으로 문제를 해결할 수도 있고, 복잡하게 비트 연산을 동원하는 경우도 있다. (이 비트열을 사용하는 방식은 알리바바에서 제시한 면접 답이라고 한다.) 하지만 꼭 유식하게 풀 필요는 없다.
마이크로소프트가 제시한 답은 다음과 같다고 들었다.
N을 8비트(1바이트) 단위로 쪼갠다. 그러면 각 숫자를 구할 수 있다. 미리 0부터 256까지 수열을 만들어 arr[n]의 값이 해당 숫자의 1비트 개수를 가리키도록 미리 저장한다. N을 8비트씩 쪼개어 배열의 인덱스로 접근하면 1비트 개수가 나온다. 이것을 계속 반복해 sum을 구한다.
8비트로 쪼갰으므로 여러 번 연산을 수행해야 한다. 복잡도는 O(N)이지만 세밀하게 보면 N/8이다. 적어도 비트 연산을 하나씩 수행하는 식의, 복잡도가 O(N)인 경우보다는 개선된다.
그러나 이 문제의 핵심은 다음 딸림 문제에 있다.
8비트가 아니라 16비트, 32비트로 배열을 만들어 사용하면 퍼포먼스가 개선되는가?
언뜻 생각하면 개선되는 것 같다. 8비트보단 16비트 단위로 크게 잘라서 한 번에 1비트의 개수를 구하면 계산이 2배 빨라지기 때문이다. 그렇다면 32비트, 더 나아가 16비트면 정말 개선될 것 같다. 그러나 이 문제는 그리 간단하지 않다. 만약 개선될 것 같다고 대답하면 함정에 빠진 것이다.

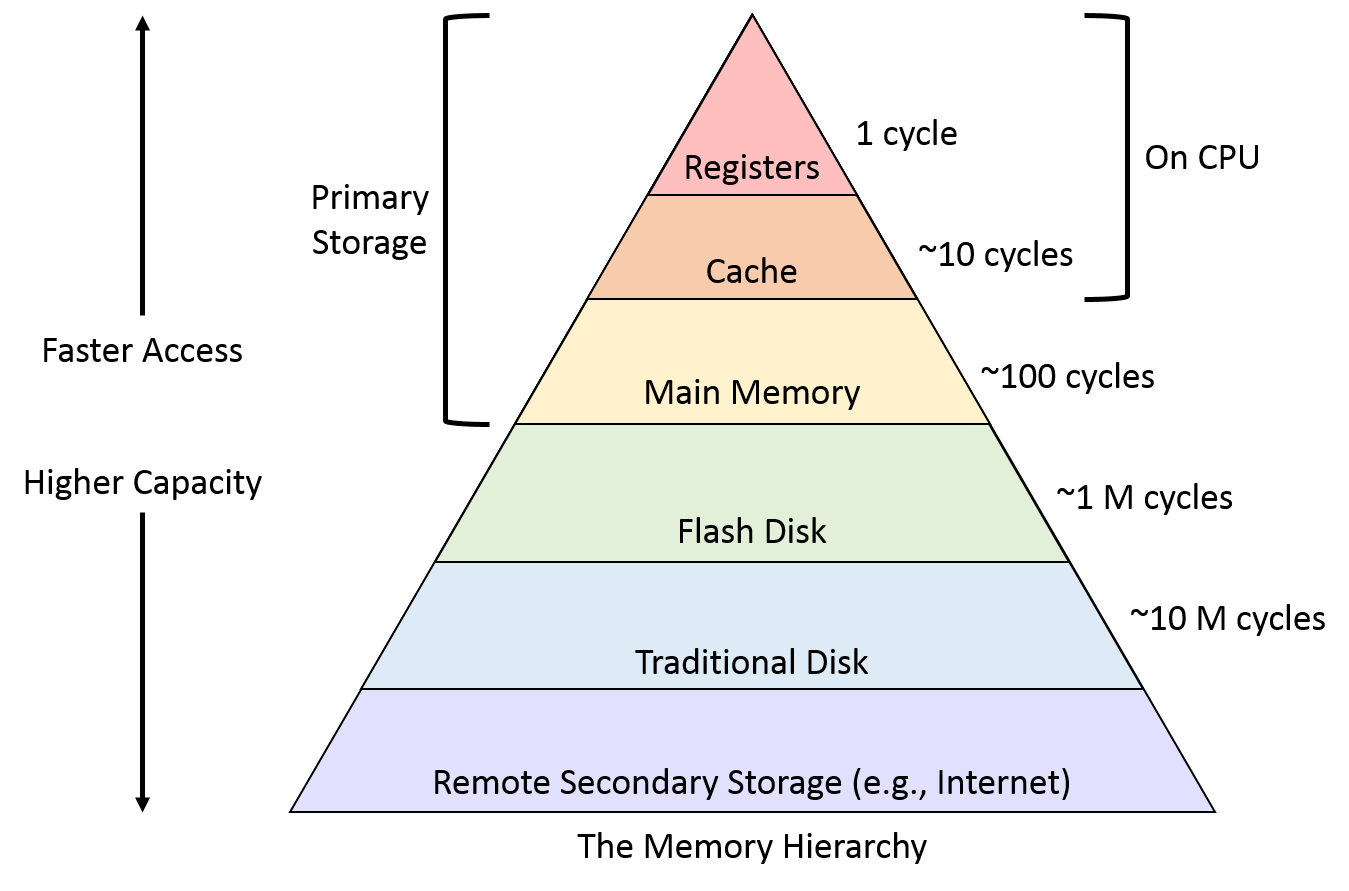
위 사진은 컴퓨터의 스토리지 장치의 계층 구조를 나타낸다. 계층의 의미는 위로 갈수록 데이터를 읽고 쓰는 속도(Access)가 빠르다. 그러나 용량(Capacity)은 비례해 줄어든다. 맨 위에 레지스터가 있고 차례대로 내려와 하드디스크에 이른다. 하드 디스크까지는 컴퓨터 하나의 장치에 속한다. 맨 밑의 Internet은 일종의 클라우드 스토리지라 보면 된다. 당연히 제일 느리다. 네트워크 준비 시간과, 네트워크 자체의 속도와 대역폭에 의존하기 때문이다.
여기서 핵심은 오른쪽의 사이클 부분이다. 정확히 표현되지 않았지만 대략 CPU 명령어 처리 속도를 말한다고 보면 될 것 같다. 레지스터는 한 명령 주기가 진행되면 데이터를 엑세스할 수 있다. 당연하다. 애초에 명령어가 레지스터를 열고 닫는 식이기 때문에 한 단위 속도에 정확히 들어맞는다. 사실 데이터를 읽고 쓴다는 행위 자체가 CPU 내부의 다양한 용도의 레지스터에 배치하는 행위다.
그러나 캐시는 길게는 10사이클까지 기다려야 한다. 괜찮은 CPU인 인텔 i7 코어의 L1 캐시도 데이터 엑세스에 4사이클이라는 시간이 걸린다고 한다. 즉, 한 쿨럭씩 CPU가 일을 할 때, 그 시간을 4배를 써야 겨우 데이터 하나를 CPU 내부 레지스터로 로드할 수 있다는 뜻이다.
컴퓨터의 핵심이라 할 수 있는 RAM을 보자. 100사이클이다. 즉, 데이터를 엑세스하는 명령어가 실행되면 그 데이터가 메모리에서 시작해 데이터 버스를 타고 주욱 진행하면서 CPU의 레지스터에 당도할 때까지 CPU는 기다리는 것이다. 무려 약 100개의 쿨럭 주기에 맞먹는다.
프로세서의 처리 속도와 스토리지에서 데이터를 읽고 쓰는 것이 언제나 느리기 때문에 이런 문제가 발생한다. 이 문제는 하드웨어적 문제이기 때문에 개선하기가 쉽지 않다. 따라서 컴퓨터 공학에서는 저런 식으로 메모리에 계층을 구분한다. 너무 느린 메모리(RAM) 대신 캐시에 원하는 데이터가 있다면 CPU의 낭비를 줄일 수 있다. 캐시는 상대적으로 더 빠르기 때문이다.

문제는 캐시는 그만큼 용량이 크지 않다. RAM이 GB 단위라면, 캐시는 거진 KB 단위다. 압도적인 차이다. 따라서 만약 원하는 데이터가 캐시에 없다면 메모리 계층을 차례대로 내려와 검색해야 한다. L1에서 시작해 L2, L3, RAM, ... 이런 식이다. HIT율에 비해 MISS율이 크면 성능은 더 떨어진다. MISS가 발생하면 낮은 메모리에 접근하면서 동시에 적당량을 덜어내 캐시에 배치해야 한다. 다음의 명령어의 효율을 위해서다.
다시 처음 문제로 돌아가보자. 8비트 단위를 16비트, 32비트 단위로 처리하면 퍼포먼스가 개선되는가? 답은 아니오다. 32비트는 논리적 주소 공간만 해도 4GB 단위다. 캐시는 커녕 RAM에 적재하기도 버거울 정도다. 그러나 8비트는 256바이트의 공간을, 16비트는 64KB 공간을 차지한다. 컴퓨터 하드웨어 사양에 따라 다르겠지만, 자칫 16비트로도 캐시를 큰 비율로 채울 수도 있어 높은 MISS율을 발생시키게 된다.
따라서 메모리의 한계를 생각하면 쪼개는 비트의 단위를 키울수록 오히려 성능은 더 악화되며, 너무 크게 쪼갠 경우, 메모리의 한계를 벗어날 수도 있는 것이다.
3. 랜덤 엑세스 vs 순차 엑세스

알고리즘을 만드는 경우 랜덤 엑세스가 더 유리하게 느껴지지만, 공학적 한계를 고려한다면 공간복잡도가 큰 경우에 순차 엑세스가 유리하다. 만약 랜덤 엑세스가 가능한 자료구조가 있다고 하자. 예를 들면 해시 테이블 같은 것이다. 이때 이 자료구조가 대용량의 데이터 처리에 사용될 수 있을까?
사용되지 못하는 것은 없지만 공학적으로 고민이 요구된다. 대용량이라면 어쩌면 메모리의 한계를 벗어날 수도 있다. 이때는 운영체제의 도움을 받아 하드 디스크에 파일로 저장해야 할 수도 있다. 그런데 랜덤 엑세스의 경우 프로그램이 원하는 곳 어디서나 접근이 가능하다(라고 기대한다). 따라서 자칫 하드 디스크에 저장된 파일의 데이터를 가져와야 할 수도 있다. 최악의 경우다. 하드 디스크만큼은 사용자들도 데이터 읽고 쓰기를 눈으로 볼 수 있을 만큼 매우 느리다. 따라서 CPU 입장에서는 심각하게 느리다.
대용량 데이터는 차라리 순차 접근이 가능한 식으로 설계하는 것이 좋다. 순차 접근식 자료구조는 실제 알고리즘에서도 순차적으로 접근해 자료를 처리해야 한다. 랜덤 엑세스보다 열등해보이지만 결코 그렇지 않다. 메모리의 한계에 따라서는 순차 접근이 최선일 때도 있다. 순차적이기 때문에 자료구조의 데이터 간에는 지역성(locality)이 있다. 가까운 데이터는 반드시 함께 사용된다. 랜덤 엑세스 자료구조는 기대하기 힘든 특성이다.
따라서 순차적으로 처리하다가 캐시 MISS가 뜨는 경우, 높은 확률로 다음 메모리 계층에서 다음 데이터 세트를 발견할 수 있으며, 대용량인 경우에는 데이터를 처리하면서 동시에 다음 데이터 덩어리를 메모리에 적재할 수도 있다. 이 방식은 대용량의 영상 프로그램이나 유튜브 영상의 처리 방식과 거의 동일하다. 영상을 볼 때는 보통은 순서대로 보기 마련이다. 따라서 스트리밍 프로그램은 현재 시청중인 부분 다음 데이터를 로드한다.
대용량 데이터가 순차 엑세스 자료구조에 적합하다면, 랜덤 엑세스 자료구조는 되도록 메모리의 한계를 고려해가며 설계해야 한다. 그래야 빠르고 효율적이다.
#. 결론
소프트웨어 개발자는 스토리지의 전송 속도를 고려해야 한다. 소프트웨어 개발이 하드웨어와 개념적으로 분리되어 발전했으나, 그럼에도 여전히 소프트웨어의 기반은 하드웨어 구조에 의존한다는 사실을 명심하자.
'IT 공부 > 컴퓨터 하드웨어 및 구조' 카테고리의 다른 글
| 함수 호출 시 스택프레임이 관리되는 원리 (어셈블리 레벨) (0) | 2023.12.26 |
|---|---|
| 2의 보수 계산법의 의미 (0) | 2023.12.26 |
| 은근히 헷갈리는 비트, 바이트 단위 정리 (0) | 2023.12.26 |
| C언어 컴파일 과정 (0) | 2023.11.15 |
| 비트(bit)와 정보의 실체 (1) | 2023.10.27 |



