1. 컴퓨터의 공학적 실체
컴퓨터의 동작 원리를 비유적으로 표현할 때, 흔히들 "컴퓨터는 0과 1로 소통한다"는 비유를 든다.
물론 "물리적으로는" 틀린 설명이다. 0과 1이란 물리적 실체가 아니라 개념이기 때문이다. 컴퓨터 장치를 뜯어 봤자 0과 1은 없다. 전기들이 배선을 타고 흐를 뿐이다.
그러나 컴퓨터는 수학 이론으로 설계된 장치다. 컴퓨터 과학은 0과 1이라는, 아니 더 정확히 말하면, 두 가지 가능성 중 하나를 선택하는 정보의 최소 단위인 비트(bit)를 처리하는 기계다. 현대 컴퓨터는 단지 그 이론을 전기적으로 구현했을 뿐이다. 따라서 물리적 실체를 떠나 0과 1이라는 관습대로 해석하는 것이 꼭 틀린 것은 아니다.
물론 이 비트(두 가지 가능성)라는 녀석을 0/1이라고 부르든, true/false라고 부르든, yes/no 라고 부르든, 톰과 제리라고 부르든 아무 상관이 없다. 그럼에도 0과 1로 생각하자는 관례가 있는 것은 부울대수 이론을 통해 복잡한 컴퓨터의 원리를 수학적으로 다루기 편하기 때문이다.
우리는 비트 0/1을 가지고 세상의 모든 정보를 표현하고 저장할 수 있다. 물론 컴퓨터는 단지 저장장치 인 것만은 아니다. 저장만으로 컴퓨터라 부를 수 있다면 종이에 휘갈긴 낙서도 컴퓨터가 되는 엉뚱한 일이 벌어질 것이다. 컴퓨터가 컴퓨터다운 이유는 바로 "처리"에 있다. 쉽게 말해 정보를 가공해서 다른 정보로 바꿀 수 있기 때문에 비로소 컴퓨터다운 것이다.
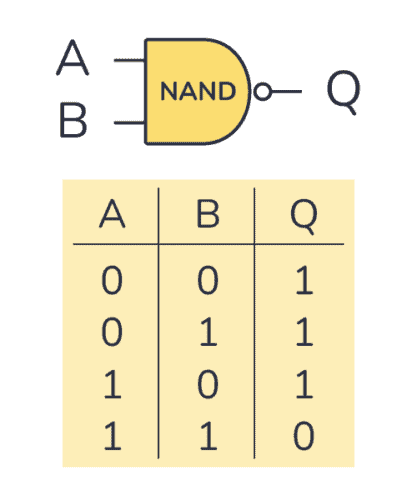
놀랍게도 컴퓨터의 모든 "처리"를 구현하기 위해서는 딱 하나의 부품만 있으면 된다. 바로 NAND 게이트다. NAND 게이트 논리로 처리할 수만 있으면 어떤 기계 장치든 컴퓨터가 될 수 있다. 아무리 복잡한 컴퓨터 장치라고 해도 그 실체는 NAND 게이트의 조합으로 환원된다. 컴퓨터 구조는 NAND 게이트를 조합해서 AND, OR, NOT, 그리고 아주 작은 메모리 장치, 가산기, CPU, ... 등등 컴퓨터 장치들을 차근차근 조립해나가 복잡한 처리를 구현한다.
괴델과 튜링의 혁신적 사고 덕분에 우리는 이 처리 과정조차 하나의 비트열로 환원시킬 수 있다. 이것이 바로 코딩이다.
단, 이 포스트에서는 처리에 대한 해석은 생략하고, 정보 그 자체의 표현에 대해 더 집중하겠다.
2. 왜 두 가지 가능성인가?
나는 처음 C언어를 배우고, 컴퓨터의 공학적 실체가 궁금해 구글링을 통해 NAND 게이트를 조합해가며 8비트 컴퓨터를 설계해본 적이 있었다. (전공자가 아니라서 간단한 교양 서적으로 깨우쳤다.. 지극히 간단한 CPU와 RAM이었다.)
그런데 의문이 하나 들었다. 왜 꼭 비트여야 하는 것일까? 당시 나는 정보의 본질을 몰랐기 때문에 그때만 하더라도 정보를 정말로 0과 1이라는 어떤 "수학적인 내용"으로 받아들였었다. 0과 1 자체에 어떤 의미가 있다고 생각했던 것이다...!
그래서 0과 1로 이렇게 복잡한 이진법 로직 게이트를 연결하지 말고 한 번에 10진법을 사용하는 것이 낫지 않을까 하는 생각이 들었다.
나는 컴퓨터를 말 그대로 (compute) 즉, 수치(number) 계산기로 생각했던 것 같다. 0과 1로 구성되었다는 말에 대해 나는 정말로 컴퓨터를 이진수 계산기로만 생각했던 것이다. 덧셈, 뺄셈을 할 수 있는 단순한 기계라고 생각했다. 너도 나도 주위에서 컴퓨터의 원리를 "정보"라는 표현보다 0, 1이라는 수 개념으로 설명했다. 때문에 당시의 내가 "정보" 자체의 원리를 깨우치지 못하고 0/1이라는 내용에 집착했었던 것이다.
나는 정보 자체의 본질과 의미론적 내용을 분리해 생각하질 못했다.
0과 1에서 비트를 읽지 않고 그 자체로 인진법 정도로 받아들였다.
3. 정보의 본질
나는 비전공자이기 때문에 정보의 본질에 대한 이해는 교양 수준에 가깝다. 어떻게든 꾸역꾸역 구글링을 통해 이해한 바에 따르면, 정보의 본질은 절대 그것을 표현하는 해석이나 내용과는 무관한 과학이라는 것이다.
예를 들어, 지금 내가 작성하고 있는 이 블로그 글의 정보를 표현하려면 어떻게 해야 할까? 나는 지금 한글을 사용하고 있으므로 한글로 정보를 표현하고 있다. 반대로 이 글을 영어로도 작성할 수 있을 것이다. 그렇다면 정보는 영어 알파벳으로 표현될 것이다.
알파벳은 26글자다. 한글은 조합을 생각하면 26자보단 많다. 그렇다면 한글로 작성한 글이 조금 더 풍부한 정보를 담고 있는 것일까?
클로드 섀넌 이전, 정보이론의 선구자 랠프 하틀리는 의미에 대한 이러한 기호적 합의는 전적으로 문화와 심리에 의존하며 거기에는 그 어떤 법칙도 없다고 말했다.
즉, 어떤 정보를 표현하기 위해 알파벳을 사용하든, 한자나 한글을 사용하든 상관없이, 상징으로 사용하는 기호와 매질 자체에는 그 어떤 본질도 없다는 것이다. 한자의 종류가 수천가지가 넘는다고 해서 중국어가 더 풍부한 정보를 품고 있는 것이 아니다. 어떤 정보를 표현하는 '기호'는 정보와 관련이 없다! 이것은 0과 1도 마찬가지다.
클로드 섀넌은 이 통찰을 확장했다. 정보의 본질을 일련의 가능한 메시지 중 하나를 선택하여 불확실성을 줄이는 정도로 측정될 수 있음으로 정의했다. 기호와 의미를 정보로부터 분리하는데 최종 성공한 것이다.
정보는 올 수 있는 여러 서로 다른 확률의 대안 N개 중 하나를 선택하는 행위로 생각할 수 있다.
위 그림은 점묘법으로 유명한 조르주 쇠라의 그림이다. 그림을 확대해서 보면 특정 색상 하나를 선택해서 일일이 점으로 찍어가며 그렸다. 독특한 분위기를 자아낸다.
사실 다른 화풍의 그림도 딱히 다를 것은 없다. 연속적으로 보일 뿐이지, 포토샵에서 픽셀 하나하나를 확대해서 보면 결국 정사각형 픽셀 덩어리에 특정 색상이 선택된 것으로 볼 수 있다.
그림을 정보로 환원해 다른 곳으로 전송해야 한다면, 픽셀 하나 하나의 색상을 일렬로 나열해 상대에게 전송하면 된다.
이때의 정보는 내용적으로는 각각의 픽셀이 선택한 "색깔"이다. 색깔이 만약 총 10가지가 있다면, 그것을 어떻게 표현해야 할까? 직관적인 대답은 "red", "blue", "yellow", .... 이런 식으로 색깔을 말하는 것이다.
그러나 정보의 본질 자체는 기호와는 무관하다. 알파벳으로 표현하든, 한글로 표현하든, 그림을 그리든, 0/1의 조합으로 배치하든, 픽셀 하나의 색깔이란 결국 10가지 가능성 중 하나가 선택되었다는 것, 이것이 중요하다.
만약 통신 장치나 컴퓨터가 내부적으로 이 10가지의 색깔 기호를 1, 2, 3, 4, ... 처럼 한 글자의 숫자로 다룰 수 있다면 아주 빠르게 이 그림의 정보를 전송하고 처리할 수 있을 것이다. 이 기호들 각각은 여러 대안 중 하나를 지목해줌으로써 다른 대안들이 올 가능성을 없앤다. 불확실성을 없앤 것이다.
4. 컴퓨터는 정보 처리 기계!
그러나 고작 그림 데이터를 위해 10가지의 서로 다른 픽셀 색깔 기호를 설계하고, 그 기호 처리 장치를 물리적으로 고안해내는 것은 공학적으로 벅찬 일이며, 그렇게 할 수 있다고 해도 낭비가 심할 것이다. 그림을 전송하는 것이 꼭 중요한 일상은 아니지 않은가.
컴퓨터는 단지 "그림" 정보만 처리/전송/저장하는 장치가 아니다. 컴퓨터는 따지자면 범용이다. 그림이라는 특정 정보 맥락에 종속된 장치가 아니다.
컴퓨터는 정보 처리 장치라고 불린다. 정보를 저장하고, 처리하고, 입력받고 출력한다. 컴퓨터가 정말 재밌고 오묘한 점은, 컴퓨터는 그 설계 시점에서 이미 정보의 "내용"과는 무관한, 즉 정보의 내용 및 맥락과 무차별적인 장치라는 점이다.
정보 그 자체는 기호와 무관하다. 알파벳이든, 히라가나든, 한글이든 어떤 기호가 오더라도 그 신호를 주거나 받는 사람 사이의 합의 하에 기호를 마음대로 고안하고 표현할 수 있다. 기호 자체는 정보가 아니다.
그렇다면 이제 정보를 처리하거나 저장하는 장치를 고안할 때 공학적, 수학적으로 핵심이 되는 사항은 간단명료해진다. 바로 어떻게 해야 수학적으로 정확하게 정보를 처리하고, 공학적으로는 기호의 낭비를 막는가이다.
픽셀에 대응될 수 있는 색깔 개수만큼 서로 다른 기호를 처리할 수 있다면 정보의 처리와 전송 속도는 굉장히 빠를 것이다. 그러나 이것은 물리적인 실현이 힘들다. 10가지 이상의 상태를 구분할 수 있는 장치는 상당히 까다로운 공학적 도전이다.
특정 맥락과는 무관하게 순수하게 정보 자체를 처리하는 것, 그리고 공학적으로도 그 구현이 간단명료한 것이 바로 비트(bit)다. 비트는 최소한의 정보 단위다. 정보란 불확실성을 소거해준다. 그렇다면 그 불확실성의 최소 단위는 비트 즉, 0 아니면 1, 혹은 yes 아니면 no이다.
부울 대수와 로직 게이트를 통해 기호의 조합으로 다른 기호를 만들어내는 게이트를 이론적 제한 없이 만들어낼 수 있다는 것이 증명되었다. (부울대수의 연산 법칙을 활용하면 테이블에서 수식을 추출해 간단하게 만들 수 있다)
또한 클로드 섀넌에 의해 정보의 불확실성 속에 숨은 확률의 원리가 정보의 압축에 사용됨으로써 정보의 최소 단위인 비트로도 효율적으로 정보를 전송할 수 있게 되었다. 비트를 쓰면 흔히 걱정되는 것은 한 정보를 표현하기 위해 너무 많은 기호의 나열이 필요한지다. 그러나 섀넌은 확률을 적용해 정보의 본질을 밝혀내었다. 즉, 자주 나오는 정보는 그다지 불확실성을 줄여주지 않으므로 정보량이 적다. 따라서 적은 비트를 할당한다. 반대로 나오기 힘든 정보라면 확률적으로 불확실성을 크게 줄여주기 때문에 정보량이 크다. 따라서 많은 비트를 할당한다.
가장 중요한 점은 비트가 정보의 최소 단위라는 점이 컴퓨터가 기호 사용의 낭비가 없는, 범용 정보 처리 기계로서 다뤄지는데 매우 중요한 기반이라는 점이다.
5. 결론
정보의 본질이란 그것이 알려짐으로 인해 얼마만큼 불확실성을 줄여줄 수 있는지 여부이며, 그 정도의 크기에 따라 정보량을 결정할 수 있다.
두 가지 가능성 중 하나를 결정하는 정보의 최소 단위인 비트(bit)와, 몇 가지 논리 게이트 처리 장치를 조합하면 기호를 다른 기호로 매핑할 수 있는 논리 게이트의 조합을 만들어낼 수 있다. 쉽게 말하면, 비트와 논리 게이트로 만들어내지 못하는 계산 장치는 없다. (물론 튜링 기계에서 벗어나진 않는다)
정보란 기호가 아니다. 0과 1의 조합이든, a, b, c, ...로 나타내든 기호 그 자체는 정보의 본질을 설명하진 않는다. 따라서 정보는 언제나 다른 기호로 매핑될 수 있다. 이 매핑이 바로 "인코딩"이다.
컴퓨터는 범용 정보 처리 장치이다. 정보를 전송하고, 처리하고, 저장한다. 이때 말하는 정보는 정보 그 자체다. 얼마나 확률적으로 새로운지 알려주는 신호다. 즉, 컴퓨터는 정보의 내용 및 사용 맥락는 무관하다. 순수하게 정보 자체를 다룬다. 그래서 온갖 프로그램에서 다양한 맥락과 인코딩을 적용해 인간이 이해할 수 있는 실질적인 기호로 매핑할 수 있다.
가산기와 같은 수학적 계산 자체도 NAND 논리 게이트와 등가다. 여기서 중요한 결론이 하나 나온다. 컴퓨터 과학에서 정보는 그 내용이 아니라 공학, 수학적으로 정보 저장과 처리의 "효율"을 따지는 방향으로 설계되었다는 것이다.
<컴퓨팅의 진수> 저자 우쥔에 따르면, 훌륭한 개발자는 모든 종류의 정보와 개체를 비트로 코딩(매핑)하는데 능숙한 사람이라고 한다. 컴퓨터가 정보의 순수한 형태인 비트를 처리하는 장치라는 것을 고려하면, 우리가 생활 속 정보를 어떻게 비트로 코딩하고 매핑시킬지에 따라 효율적이고 이해하기 쉬운 알고리즘이 나올 것이다.
'IT 공부 > 컴퓨터 하드웨어 및 구조' 카테고리의 다른 글
| 함수 호출 시 스택프레임이 관리되는 원리 (어셈블리 레벨) (0) | 2023.12.26 |
|---|---|
| 2의 보수 계산법의 의미 (0) | 2023.12.26 |
| 은근히 헷갈리는 비트, 바이트 단위 정리 (0) | 2023.12.26 |
| C언어 컴파일 과정 (0) | 2023.11.15 |
| 메모리 계층 구조와 알고리즘의 공학적 한계 (0) | 2023.11.03 |



