1. 소스코드도 문자열에 불과하다!
소스 코드의 본질은 문자열이다. 대부분 이클립스나 비주얼 스튜디오 코드, 인텔리제이와 같은 IDE 개발 환경에서 개발하기 때문에 간과하기 쉽다. 소스코드를 작성하고 단축키를 누르면 즉시 빌드되고 실행되기 때문이다. 마치 소스코드가 그 자체로 실행되는 느낌이다. 그러나 소스코드 데이터의 본질은 "문자"다. 컴퓨터가 아니라 인간이 읽고 이해하는 파일이다. 따라서 사실 메모장에서 코드를 작성해도 아무 문제가 없다.
(물론 정말로 메모장으로 코딩하는 사람은 없을 것이다.... ;)
그런데 문자열을 다루는 순간, 우리는 필연적으로 인코딩 문제를 신경쓸 수 밖에 없다.(링크) 유니코드인지 아닌지, 문자셋이 유니코드라면 그것을 어떻게 구체적으로 인코딩 했는지에 따라 깨짐 문제가 발생할 수 있다.
소스 코드 또한 아직 컴파일되지 않은 시점에서는 그저 문자열 데이터에 불과하므로 문자셋과 인코딩 문제를 그대로 안고 간다. 자바 컴파일러(javac.exe) 프로그램이 소스 코드 파일을 읽어들일 때, 이 코드를 어떻게 인식하느냐에 따라 문제가 생길 수도 있기 때문이다.
그렇다면 자바 컴파일러(javac.exe)는 소스코드(.java 파일)의 문자열을 어떻게 인식하는가? 공식 문서를 보면 특별히 java.exe 명령어 옵션으로 구체적인 인코딩을 지정하지 않는 이상, 시스템의 기본 인코딩을 그대로 사용한다고 나와 있다.
Tools Reference
You can use the javac tool and its options to read Java class and interface definitions and compile them into bytecode and class files.
docs.oracle.com
" Specifies character encoding used by source files, such as EUC-JP and UTF-8. If the -encoding option isn’t specified, then the platform default encoding is used. "
일반적으로 흔히 사용되는 JavaSE 11 (JDK11) 버전의 javac 스펙 문서를 보면, 위와 같이 -encoding 옵션을 통해 소스 코드 파일의 인코딩을 지정해줄 수 있으며, 만약 지정되지 않은 경우 디폴트로 "시스템의 기본 설정"을 따른다고 한다.
만약 윈도우에서 소스 코드를 작성하고, 이 소스 코드의 인코딩이 UTF-8 이라고 하자. 그리고 javac를 통해 컴파일하면 아래와 같은 에러를 만난다.
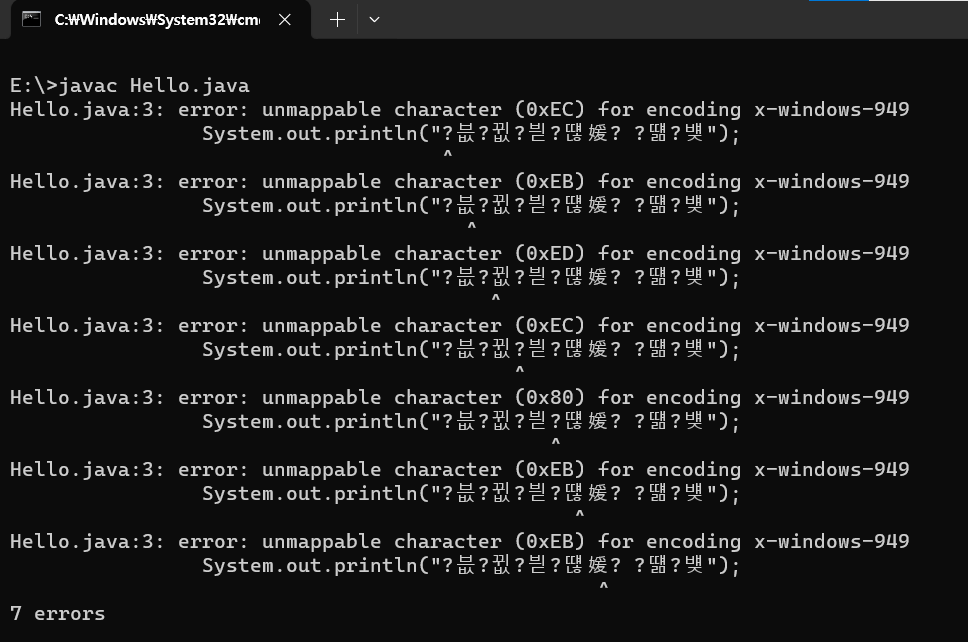
인코딩에 문제가 발생하고 있다. 이유는 javac.exe 컴파일러가 윈도우 시스템의 디폴트 인코딩으로 소스코드 파일을 해석하기 때문이다. 윈도우의 시스템 디폴트 인코딩은 아래와 같이 CP949다.

현재 시스템의 디폴트 인코딩은 CP949다. 따라서 javac.exe도 디폴트로 CP949로 소스 코드 데이터를 이해할 것이다. 그런데 소스 코드의 인코딩은 UTF-8이다. 인코딩이 같질 않으니, 한글로 작성한 부분을 인식하지 못하는 것이다.
따라와 아래와 같이 인코딩 옵션을 설정해줘야 한다.

아무런 에러 없이 정상 작동하는 것을 볼 수 있다.
솔직히 메모장에다가 소스코드를 작성할 확률은 0%에 가까우므로, 평생 개발하면서 이 문제를 마주할 일 따위는 없을 것이다. 이클립스나 인텔리J가 알아서 다 설정해주기 때문이다.
다만 소스코드의 기본이 문자열이고, 문자열과 관련된 문제의 대부분은 인코딩 설정과 관련된 것이므로 언젠가는 블로그에 정리해보는 것이 좋을 것 같아 이런 재밌는 실험을 해보았다.
'IT 공부 > 자바와 웹 애플리케이션' 카테고리의 다른 글
| [인텔리제이] - 톰캣 실행과 설정 관리 및 프로젝트 배포 환경 (0) | 2024.01.01 |
|---|---|
| [인텔리제이] - 자바 웹 프로젝트 설정에 대한 각 요소의 의미 (0) | 2024.01.01 |
| [자바] - unnamed package의 문제점과 JDK의 클래스패스 설정 방법들 (0) | 2023.12.31 |
| [자바] - Java 플랫폼을 둘러싼 모든 개념들 총정리 (0) | 2023.12.31 |
| [자바] - 한글이 깨지는 문제의 원리 (0) | 2023.12.15 |



