1. 문자열과 인코딩
문자열과 관련된 문제를 다루기 위해서는 인코딩(encoding)의 원리를 알면 된다.
컴퓨터는 0과 1로 이루어진 비트로 정보를 처리한다. 따라서 컴퓨터가 정보 처리를 마친 후에 그것을 우리(인간)가 이해하기 위해서는 0과 1로 이루어진 외계어를 사람이 이해하는 기호로 바꿔야 한다. 이 과정을 인코딩(encoding)이라 부른다.
문자열도 마찬가지다. 문자도 정보이므로 이것을 컴퓨터로 작업하기 위해서는 0과 1로 바꾸어 처리해야 한다. 그리고 그 결과를 이해하기 위해 0과 1로 이루어진 순수한 정보를 사람이 알고 있는 알파벳으로 바꿔야 한다.
물론 이때는 표준을 통일시켜 모두가 같은 인코딩 방식을 따라야만 비로소 유용할 것이다. 누군가는 A를 100이라고 하고, 누군가는 101이라고 하면 세상에 혼란이 올 것이다! 따라서 ANSI(미국 국가 표준 협회)나 유니코드 협회 등 표준 기관에서 인코딩 규칙을 설정하고 모든 개발자들은 그 원칙을 따른다.
표준 기관은 알파벳이나 특수문자를 특정 숫자(고유 번호)에 매칭시킨다. 유니코드(Unicode)가 가장 대표적이며, 이 규칙이 정리된 유니코드 테이블을 보면 거의 모든 나라의 알파벳과 특수 기호를 각각의 고유 번호에 매핑시킨 것을 볼 수 있다.


위 그림의 테이블이 유니코드다. 알파벳도 있고, 특수문자도 있고, 한글도 있다! 숫자에 A나 C와 같은 문자열이 포함되어 있는데 다름 아니라 16진수로 표현된 것일 뿐이다. 링크를 따라가면 온갖 문자(한자, 히라가나 등)의 고유 식별 번호를 알아낼 수 있다.
그런데 잠깐! 아직 이 매핑 자체는 인코딩과 관련이 없다! 즉, 유니코드(Unicode)는 인코딩(Encoding)이 아니다. 유니코드나 아스키코드는 문자 집합(character set)이라 불리며, 문자를 숫자에 매핑시킨 것 그 이상, 그 이하도 아니다.
유니코드나 아스키코드는 단지 알파벳과 특수기호를 고유 번호에 매칭시켜 모두가 일관적으로 기호를 식별(identify)할 수 있도록 만든 약속일 뿐이다. 고유 번호를 구체적인 비트와 혼동하지 말자. 각 알파벳에 매핑된 고유 번호 자체 또한 여전히 기호다! 즉, 아직 인코딩되지 않은 것이다.
인코딩은 바로 그 문자 집합의 기호들을 어떻게 컴퓨터 내부에 저장하고 처리할 것인지 공학적으로 구현한 것이다. 예를 들어, "A"(고유번호: U+0041)는 1바이트 크기의 "01000001"로 구현하는 것처럼 구체적인 구현 규칙이 바로 인코딩인 것이다.
같은 유니코드 문자 집합이라도 어떤 비트열로 컴퓨터 내부에 저장할 것인가는 구체적으로 어떤 인코딩 방식을 사용하느냐에 따라 다 다르다. 유니코드에는 여러가지 방식의 인코딩이 있다. 이 중 개발자 세계에서 가장 대중적인 방식은 UTF-8이며, 가장 친숙하고 유명하다.
2. 자바 애플리케이션 내부의 문자열 인코딩
자바 애플리케이션은 문자열을 char, String 데이터 타입으로 다룬다. String은 내부적으로 char 타입의 배열을 사용하므로, 사실상 char 타입이 문자와 관련된 데이터 타입이다.
자바는 char 타입을 2바이트로 고정시켜 사용한다. 자바는 유니코드를 기본 문자 집합(Character Set)으로 취급하며, 자바 애플리케이션 내부에서 유니코드 문자열을 UTF-16으로 인코딩해 사용한다.
UTF-8이나 UTF-16이나 모두 유니코드 기반이다. 그러나 구체적인 인코딩 방식은 서로 다르다. UTF-8이 알파벳의 종류에 따라 저장 크기가 달라지는 가변 코드라면, UTF-16은 알파벳 종류에 관계 없이 모든 기호가 16비트(2바이트)로 저장된다.
아래 공식 문서의 설명을 보자. 자바는 UTF-16으로 인코딩한다고 명시하고 있다.
Chapter 3. Lexical Structure
The program consisting of the compilation unit (§7.3): package testPackage; class Test { public static void main(String[] args) { String hello = "Hello", lo = "lo"; System.out.print((hello == "Hello") + " "); System.out.print((Other.hello == hello) + " ")
docs.oracle.com
"The Java programming language represents text in sequences of 16-bit code units, using the UTF-16 encoding."
아마 자바는 내부적으로 메모리 효율을 따지기 보단, 문자열 데이터를 처리하는데 있어 효율과 편의를 위해 2바이트로 고정시킨 UTF-16을 채택했을 것이라 생각한다. 왜냐하면 자바 애플리케이션의 주요 목적은 데이터를 처리하는 데 중점을 두기 때문이다. 알파벳 종류에 관계 없이 모두 동일한 바이트 크기를 가진다면 알고리즘을 코딩하기 편리할 것이다.
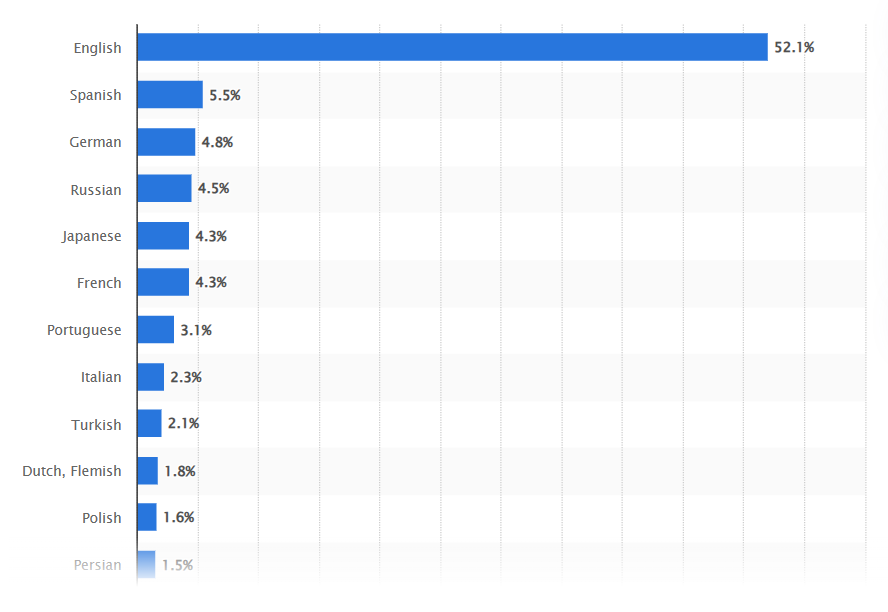
※ 반대로 데이터를 전송하거나 저장하는 용도로는 UTF-8이 더 나을 수도 있다. UTF-8에서 한글은 3바이트나 차지하지만 영어 알파벳은 고작 1바이트만을 차지하기 때문이다. 위 통계처럼, 이 세상을 오고가는 대부분의 데이터가 영어 알파벳 기반인 것을 생각하면 전송과 저장에 UTF-8이 사용되는 것은 아주 효율적이다.
물론 자바 애플리케이션 내부적으로는 인코딩의 상세 사항에 대해서 깊게 파고 들지 않아도 상관은 없다. 충분히 추상화된 String 타입을 바탕으로 개발이 가능하기 때문이다. char가 2바이트라는 것 정도만 알아도 큰 문제는 없다.
자바 애플리케이션 개발자는 데이터를 다루는 복잡한 구현 사항을 신경쓰지 않고 철저하게 원하는 로직에만 집중하면 된다. 자바 진영에서 String 문자열을 2바이트로 사용한다고 했으면 거기까지만 이해한 뒤, 더 이상 깊게 들어가지 않아도 큰 문제는 없다.
3. 외부와 문자열 데이터를 주고받을 때의 문제점
그러나 문제는 자바 애플리케이션이 "외부"와 데이터를 주고 받을 때다.
어디까지나 내부적으로! String을 2바이트 UTF-16 유니코드로 사용하는 것이지, 애플리케이션이 외부와 문자열 데이터를 주고 받을 때는 복잡한 상황이 연출된다.
(여기서 말하는 외부란 자바 애플리케이션의 단위를 말한다. 즉, 자바 애플리케이션은 JVM이 동작시키고, JVM은 Windows, Mac과 같은 OS 위에서 동작하는 응용 프로그램이다. OS 또한 애플리케이션 입장에서는 외부인 것이다.)
왜냐하면 애플리케이션이 외부와 송수신하는 데이터 비트열(0, 1)이 어떤 인코딩 방식을 따랐는가에 따라 해석을 다르게 해야하기 때문이다. 애플리케이션 내부에서만 String을 다룰 때는 굳이 구현 사항까지 신경쓰지 않아도 괜찮았지만, 외부와 송수신을 할 때는 0111010.. 비트열 레벨까지 내려가서 작동 방식을 고민해야 한다.
예를 들어, 컴퓨터에 저장된 어떤 "파일"에서 데이터를 읽고 싶다고 하자. 파일은 내 컴퓨터에 있으나 자바 애플리케이션 입장에서는 OS를 거쳐 JVM 내부로 데이터가 전달되므로 외부 송수신에 속한다. 바이트 단위로 끊어보니 [11101100], [10010101], [10001000], [11101011], [10000101], [10010101] 이렇게 총 6개의 바이트를 읽었다고 하자.
아이고, 도대체 이게 무슨 문자일까???
0과 1로 이루어진 이 비트열을 도대체 어떤 인코딩으로 해석해야 할까? 1~3바이트씩 끊어서 UTF-8로 해석하면 좋을까? 2바이트씩 끊어서 UTF-16으로 이해해야 할까? 아니면 CP949와 같이, 유니코드가 아닌 다른 문자열 세트를 기반으로 하는 인코딩을 써야 하는 것일까?
반대의 상황 즉, 자바 애플리케이션이 문자열을 외부로 송신할 때도 똑같은 문제가 발생한다. 자바의 String 데이터를 도대체 어떤 인코딩으로 외부 사용자에게 전달해야 할까? UTF-8일까? 아니면 UTF-16 그대로 송신해도 괜찮을까?
4. 자바가 외부와 데이터를 주고 받는 방식
자바는 스트림(stream)을 통해 외부 장치와 IO(input, output)를 한다.
이렇게 주고받는 데이터가 문자열일 때는, 자바 가상 머신은 이 관문에서 내부(외부)의 데이터를 외부(내부)로 보낼 때, 어떻게 인코딩/디코딩을 해야 하는지 자동으로 판단한다.
만약, 자바 가상 머신이 자신의 인코딩 설정을 UTF-8로 했다면, 01110110110101.... 로 이어지는 외부에서 온 데이터 스트림을 UTF-8로 해석한다. 011011011... 데이터를 UTF-8 형식이라고 판단하고 적절하게 해석해 애플리케이션 내부로 넘긴다. 이 과정에서 UTF-8 데이터 스트림은 자바 애플리케이션이 사용하는 UTF-16 스트림으로 변환된다.
반대 방향으로 데이터를 외부로 넘길 때는 UTF-16(자바 애플리케이션 내부 인코딩)을 UTF-8 스트림으로 변환시켜 외부로 송출할 것이다.
(※ 참고. 스트림을 특별히 문자열로 열지 않는다면 자바는 데이터를 비트열 모양 그대로 들고 오거나 외부로 전달한다!! 인코딩은 본질적으로 '문자열'과 관계 있는 기술이기 때문이다.)
그렇다면 이것은 어떻게 설정되는 것일까? 자바 가상 머신은 외부와의 관문을 통과하는 데이터 스트림 10110101...의 인코딩을 자동으로 설정한다는데, 무엇을 근거로 설정하는 것일까?
그 답은, JVM은 자신을 동작시키는 컴퓨터 OS의 시스템 환경 설정에 따라 문자열 인코딩 방식을 자동으로 결정한다는 것이다. 아래는 자바 공식 문서의 설명이다. 링크
Every instance of the Java virtual machine has a default charset, which may or may not be one of the standard charsets. The default charset is determined during virtual-machine startup and typically depends upon the locale and charset being used by the underlying operating system.
예를 들어, Windows에서 현재 시스템의 인코딩 방식을 보면 아래와 같다. 윈도우는 "CP949"라는 인코딩을 사용한다. (대부분의 한글 윈도우 사용자는 CP949일 것이다.)

그리고 JVM의 현재 인코딩(character set)을 보려면 다음 링크의 간단한 메소드를 통해 알아낼 수 있다. (링크) 그 결과는,
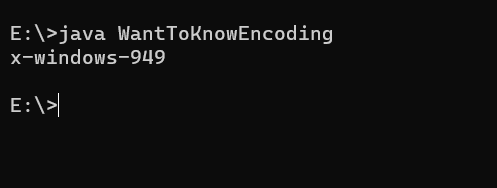
CP949다. 즉, 윈도우 시스템 설정과 똑같다! 자바는 JVM의 인코딩을 자동으로 현재 시스템 플랫폼 환경에 맞게 설정한다는 것을 알 수 있다. 따라서 System.in/out이나 File 등 외부 문자열을 다룰 때는 CP949를 디폴트 인코딩으로 사용한다.
호기심이 들어 리눅스(우분투)를 돌려서 같은 작업을 해봤고, 그 결과는 아래와 같다.
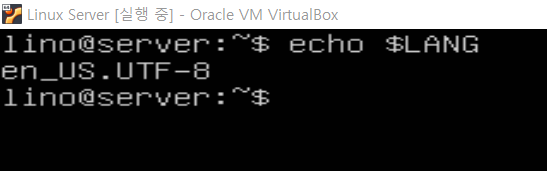
먼저 리눅스 자체의 시스템에 설정된 기본 인코딩은 UTF-8이다.
그리고 윈도우에서 했던 예제와 똑같은 코드로 구성된 클래스를 동작시켜 JVM의 인코딩 방식을 확인해보니 역시나 리눅스 시스템과 똑같은 UTF-8이 나온다. 똑같은 코드인데도 윈도우는 CP949, 리눅스는 UTF-8이 사용되는 것이다.
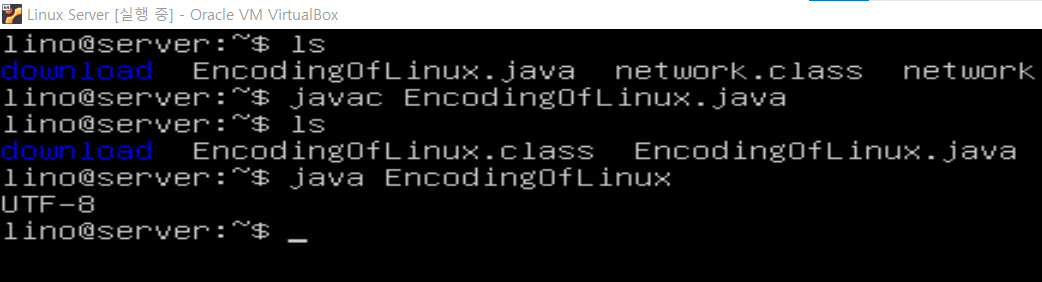
자바 가상 머신(JVM)은 윈도우에 있으면 윈도우의 인코딩인 CP949를, 리눅스에 있으면 리눅스의 인코딩인 UTF-8로 자신의 시스템 환경을 맞춘다는 것.
5. 결론: 한글이 깨진다면 인코딩 잘못! (ex. FileReader/Writer 문제)
결론적으로, 한글이 깨지는 이유는 자바 JVM이 외부와 연결된 스트림으로 문자열 String 데이터를 처리하고 읽거나 쓸 때 인코딩이 잘못 설정되었기 때문이다.
예를 들어, 자바 문자열 스트림인 FileReader/FileWriter는 JVM의 디폴트 인코딩을 바탕으로 데이터 스트림 0101110101... 을 해석한다.
그런데 읽고자 하는 텍스트 파일이 UTF-8을 사용해 저장했다면 어떻게 될까? (메모장 프로그램의 기본 인코딩은 UTF-8이다.) 이 파일을 FileReader를 이용해 데이터를 가져온다면 한글은 깨진다.
왜냐하면 메모장 파일의 데이터 스트림 1101011001.... 은 UTF-8로 인코딩되어 있는데, 이것을 JVM이 읽어 해석할 때는 시스템의 디폴트 인코딩인 CP949로 해석하기 때문이다. 마치 프랑스어를 스페인어로 해석하는 꼴과 같다.
이 문제의 원인은 외부 환경과 JVM 사이의 인코딩이 매칭되지 않아 실패한 것으로 간주할 수 있다. 따라서 이 문제를 해결하기 위해서는 JVM에게 외부 파일과 입출력을 할 때 1011001100... 로 들어오는 데이터 스트림을 UTF-8로 생각하라고 알려줘야 한다.
예를 들어, 아래와 같은 ReadFileUTF8.java 소스코드가 있다.
public class ReadFileUTF8 {
public static void main(String[] args) throws Exception {
FileReader fr = new FileReader("E:\\just test\\encoding.txt");
int data = 0;
while ( (data = fr.read()) != -1 ) {
System.out.print( (char)data + " " );
}
}
}외부 파일로부터 입력 스트림을 열어서 문자열 데이터를 가져오는 간단한 프로그램이다.
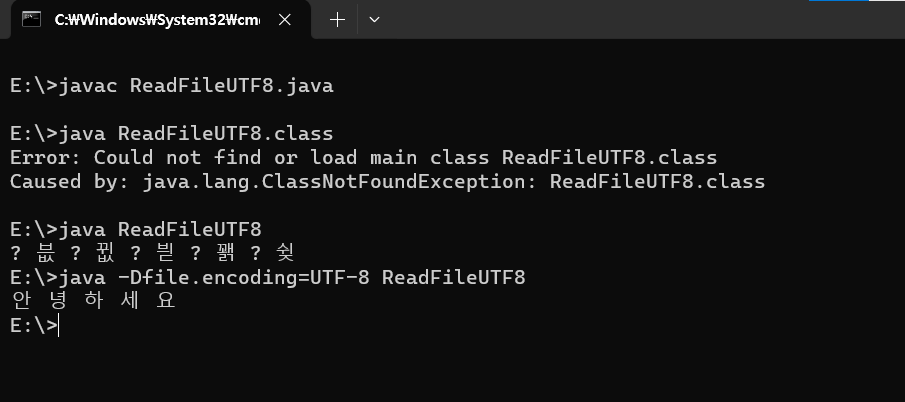
이 소스코드를 컴파일하고 Windows에서 실행하면 "? 븞 ? 뀞 ? 븯 ? 꽭 ? 슂" 이라는 이상한 문자열이 뜬다.
파일의 데이터가 UTF-8로 인코딩된 데이터인데, 그것을 JVM이 CP949로 디코딩 했기 때문이다. 결과적으로 CP-949으로 비트열을 해석하고 자바 애플리케이션의 내부 인코딩인 UTF-16으로 변환했다. 깨질 수 밖에 없다. 프랑스어를 스페인어로 해석한 꼴이다.
이를 해결하기 위해서는 옵션을 사용한다. java -Dfile.encoding=UTF-8 옵션은 JVM의 파일 입출력 시 시스템 인코딩 설정을 변경하는 옵션으로, 파일 IO 입출력 시 어떤 인코딩을 사용해야 하는지 알려준다.
이렇게 하면 비로소 JVM은 외부 파일의 데이터 비트열을 CP949가 아니라 UTF-8로 해석한다. 예시의 텍스트 파일이 UTF-8로 작성되었으므로 올바르게 인식되어 자바 애플리케이션에 전달해줄 것이다.
(※ 이 옵션은 System.out 표준 출력 스트림에는 영향을 끼치지 않는다. 만약 영향을 줬다면 쉘 프로그램이 JVM으로부터 받은 출력 데이터가 UTF-8로 해석된 결과일 것이므로 CP949로 해석하는 프롬프트에서는 마찬가지로 문자열이 깨질 것이다.)
6. 여담 : 이클립스와 인텔리제이 뷰어의 한글 깨짐 문제
이클립스, 인텔리제이 사용 시 한글이 깨지는 문제도 같은 원리다.
이클립스는 javaw를 통해 소스코드를 콘솔 환경을 매개하지 않고 IDE 단독으로 실행한다.
(※ IDE는 콘솔로의 표준 입출력을 자신이 가로채서 자신의 뷰어에 출력시키는 방식이다. IDE는 통합 개발 환경이므로, 개발자가 콘솔 프로그램을 일일이 열어서 사용하게 하는 것보다 IDE 자체의 콘솔 뷰어 프로그램으로 개발자의 코드를 실행하는 것이 좋기 때문이다.)
자바의 디폴트 JVM 인코딩은 Windows의 설정에 따라 CP949다. 따라서 System.out 표준 출력 스트림에 출력할 때, 애플리케이션 내부의 문자열 데이터 스트림을 CP949로 인코딩해서 표준 출력 스트림에 데이터를 전달한다. 즉, 표준 출력 스트림의 데이터 110110101... 의 실체는 CP949로 인코딩 된 문자열이다.
이클립스의 콘솔 뷰어에서 한글이 깨진다면, 이클립스 콘솔 뷰어의 인코딩이 UTF-8로 설정되었기 때문이다. 자바는 CP949 문자열을 보냈는데, 이클립스는 이걸 UTF-8 로 해석하니 깨진다.
실제로 이클립스의 설정을 보면 아래와 같이 설정된 것을 확인할 수 있다.
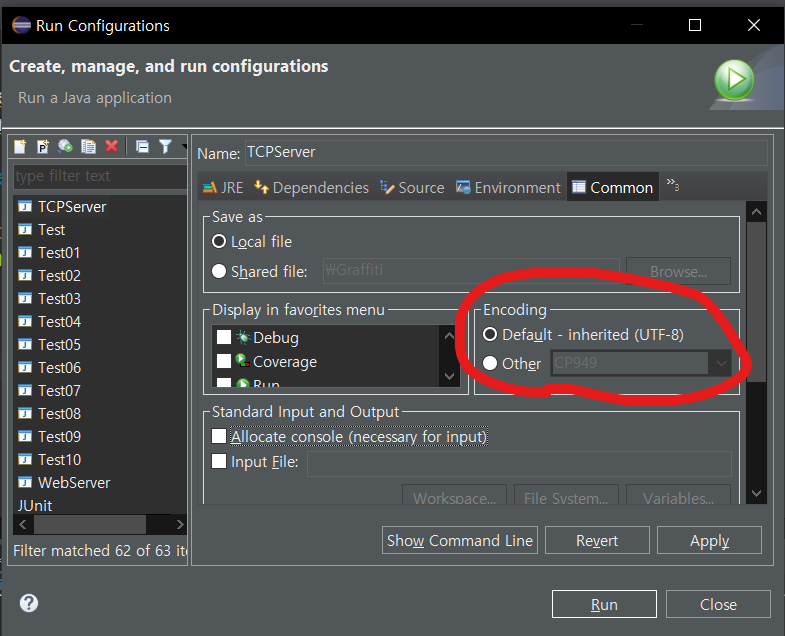
이것은 이클립스IDE가 제공해주는 콘솔 뷰어의 문자열 해석 방식을 설정해준다. 따라서 인코딩을 바꾸면 쉽게 해결된다. [Other] 항목을 선택해 CP949로 바꾸자.
(※ javaw.exe는 JDK에서 제공하는 프로그램으로서, java.exe와 달리, 콘솔 화면이 매개하지 않는 프로그램을 실행할 때 사용할 수 있도록 만든 JavaSE 스펙의 프로그램이다. 대표적으로 그래픽 인터페이스 프로그램(GUI)을 사용하는 경우 javaw.exe를 활용한다. 이런 프로그램은 유저와의 콘솔 상호작용이 필요 없으므로 javaw를 통해 새로운 프로세스로 열어서 실행하는 것이 권장된다.)
인텔리제이도 똑같은 원리로 한글이 깨진다. 자바 JVM의 디폴트 인코딩은 CP949인데, 이것을 인텔리제이의 콘솔 뷰어가 UTF-8로 해석하니 깨지는 것이다. 문제의 해결은 JVM에게 표준 입출력 스트림에 문자열을 띄울 때는 UTF-8로 인코딩하라고 해야 한다.
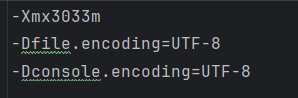
위와 같이 Help 항목의 Edit Custom VM option을 조정해준다.
인텔리제이의 문제 해결은 이클립스와는 약간 다른 접근법인데, 이클립스가 JVM의 인코딩은 그대로 두고 자신이 내장하고 있는 콘솔 뷰어의 인코딩을 CP949로 바꿔버린다면, 인텔리제이는 자신이 내장하고 있는 콘솔 뷰어의 인코딩은 그대로 두는 대신, JVM의 인코딩 시스템을 UTF-8로 바꿔버리는 차이가 있다.
'IT 공부 > 자바와 웹 애플리케이션' 카테고리의 다른 글
| [인텔리제이] - 톰캣 실행과 설정 관리 및 프로젝트 배포 환경 (0) | 2024.01.01 |
|---|---|
| [인텔리제이] - 자바 웹 프로젝트 설정에 대한 각 요소의 의미 (0) | 2024.01.01 |
| [자바] - unnamed package의 문제점과 JDK의 클래스패스 설정 방법들 (0) | 2023.12.31 |
| [자바] - 자바 컴파일러가 인식하는 소스 코드의 기본 인코딩 설정 (0) | 2023.12.31 |
| [자바] - Java 플랫폼을 둘러싼 모든 개념들 총정리 (0) | 2023.12.31 |



