1. 로깅 시스템과 Log4j2 라이브러리
로그(log)란 소프트웨어 개발 과정, 혹은 프로그램 작동 시 발생하는 이벤트에 대한 기록을 말한다. 블랙박스로 주행 중, 주차 중에서 발생하는 이벤트를 기록하는 것과 똑같은 목적이다. 소프트웨어에서 로그는 디버깅이나 작동 추적, 모니터링, 사용자 데이터 분석 등에 활용하기 위해 온갖 기록을 모으는 시스템이다. 물론 대부분의 로그 기록은 오류 검증 및 보안을 주된 목적으로 활용된다.
로그 데이터는 최종적으로 인간이 읽고 이해해야 하기 때문에 텍스트로 저장(리포트)되며, 콘솔 화면(stdout, stderr)에 출력하거나 파일에 기록하고 파일을 열람해 살펴볼 수 있다.
이렇게만 보면 단순히 Console.log()나, System.out.println() 과 같은 메소드를 활용하면 될 것 같지만, 로직 안에 복잡한 로깅(logging) 로직이 포함되는 경우 코드를 읽기도 어렵고, 무엇보다 나중에 서비스를 배포할 때는 로깅 로직이 적힌 모든 부분에 접근해서 제거하거나 수정해야 하는 번거로움이 있다.
이를 위해 독립적으로 로깅 시스템을 관리하게 되었으며, 자바 백엔드 진영에서 가장 많이 활용되는 로깅 라이브러리는 log4j2다. 아파치 재단에서 오픈 소스로 관리하는 라이브러리이며, 한때는 보안 문제가 이슈였으나 현재는 업데이트되어 괜찮아졌다고 한다.
2. Log4j2 라이브러리
log4j2를 사용하기 위한 중요한 개념은 레벨(level)과 어펜더(Appender)가 있다.
2-1. 로그 레벨
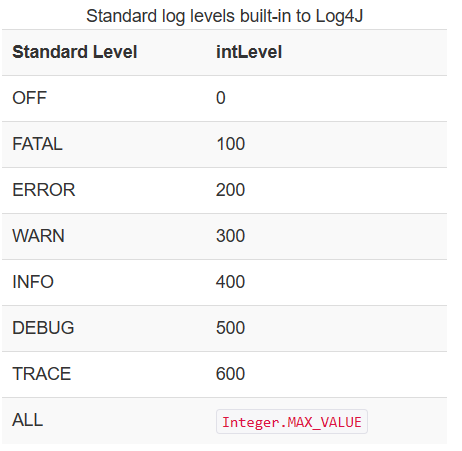
로그 레벨은 로그의 대상을 조정하는 것을 말한다. 온갖 이벤트가 발생할 때, 해당 이벤트의 중요도에 따라 어떤 것은 기록하고, 어떤 것은 기록하지 않는 것을 말한다.
로그의 중요도는 개발자가 작성하는 메소드로 결정된다. 예를 들어, log.error() 메소드는 error 레벨의 로깅이고, log.trace() 메소드는 trace 레벨의 로깅이다.
로그 레벨의 조정은 최저점을 명시한다. 예를 들어, 레벨을 ERROR로 설정하면 이벤트 중 FATAL(심각), ERROR(오류) 만 기록한다. 레벨을 INFO(정보)로 설정하면 FATAL, ERROR, WARN, INFO만 기록하는 식이다.
개발을 할 때는 최대한 방어적 프로그래밍 즉, 오류를 잡아내는 것이 중요하다. 따라서 개발 시에는 보통 INFO, DEBUG 정도로 낮게 설정하고, 배포 후 서비스될 때는 중요 로그만 기록할 수 있도록 WARN, ERROR로 설정한다. 서비스를 운영할 때 레벨을 TRACE와 같이 너무 낮은 레벨로 설정해버리면 서버에 엄청난 양의 로그 데이터를 저장하게 되며 이는 큰 비용으로 이어진다.
2-2. 어펜더
어펜더는 로그 기록을 어디에 보낼 지 결정하는 것을 말한다. 보통 리포트의 목적지로는 콘솔 화면과 파일이 있다. 개발할 때에는 개발자가 직접 로그 기록을 보기 위해 콘솔에 출력해서 직접 읽는 편이지만, 운영 시에는 파일에 로그기록을 저장하는 것이 좋다. (상식적으로, 백엔드 개발자가 24시간 콘솔 화면을 감시할 수 없기 때문이다.) 물론 이 파일은 중요한 사용자 데이터와 보안 정보가 담겨 있기 때문에 아무나 함부로 열람해서는 안 될 것이다.
3. 코딩 및 레벨과 어펜더 조정 방법
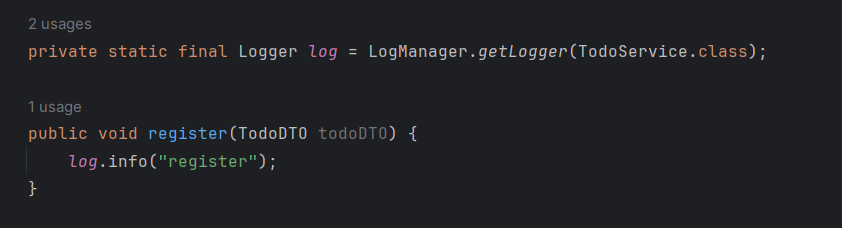
공식 문서의 권장 사항에 따라 위와 같이 작성해 사용하면 된다. 세부적인 원리를 파악하기 보단 사용 방법을 숙지만하면 될 것이다.
import org.apache.logging.log4j.Logger;
import org.apache.logging.log4j.LogManager;Logger와 관련된 같은 이름의 클래스가 꽤 있기 때문에 위 패키지를 import 해야 한다.
log.info() 혹은 log.error(), log.trace(), log.debug(), ... 등을 사용해 메시지를 어펜더에 전달한다. 여기까지다. 특별히 어려운 것은 없다. 보통 정보를 보고 싶으면 info(), 디버깅할 때 내부 값을 추적하고 싶다면 debug() 이런 식으로 쓰지만 본인이 자유롭게 판단해서 사용하면 된다.
그리고 개발자기 직접 레벨과 어펜더를 조정해주면 된다. 이것은 <log4j2.xml>을 사용하면 되며, 구체적인 기록 방법은 케이스별로 공식 홈페이지에 나와있다.
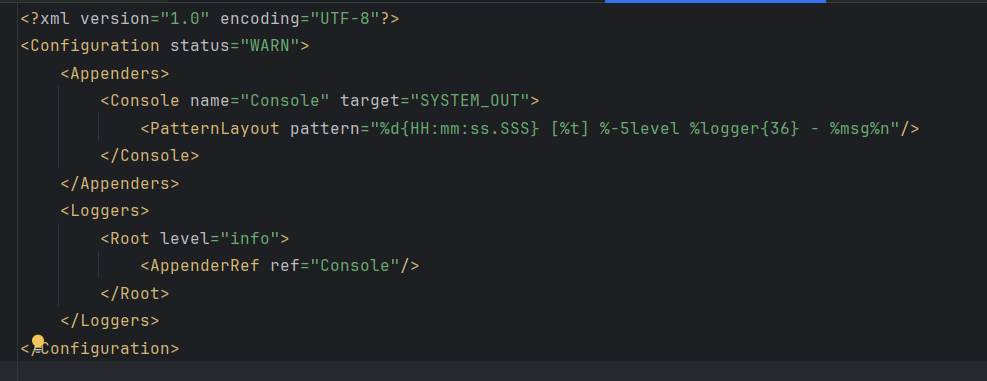
<Loggers>로 레벨을 조정하고, <Appenders>로 어펜더(file or console)를 지정하고 있다.
<Loggers>의 <Root>는 모든 최상위 부모 설정이다. level이 바로 위에서 언급한 로그 레벨이다. "INFO"로 지정했으니 INFO 레벨을 포함한 위 레벨 항목들이 로그에 기록될 것이다. 예를 들어, 만약 이 level을 INFO로 설정하지 않고 ERROR로 설정했다면, log.info() 항목은 어펜더에 로깅되지 않을 것이다!
<Loggers>는 아래처럼 구체적인 로깅 대상 클래스를 지정할 수도 있다.
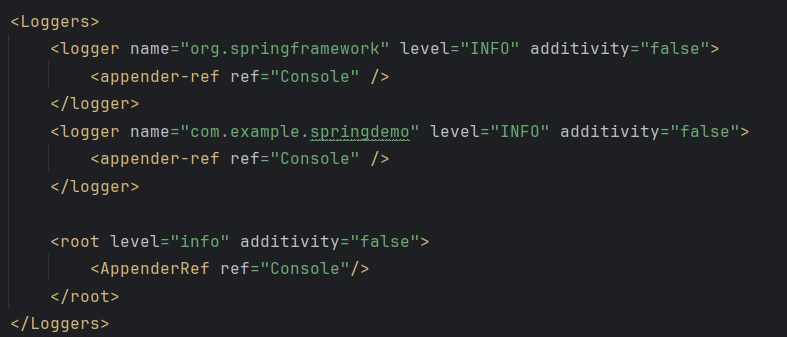
각각의 클래스를 로깅할 때 개별적인 레벨을 지정할 수도 있다. 예를 들어, MyBatis의 Mapper 인터페이스를 대상으로 level을 TRACE로 설정하면 구체적인 SQL 쿼리문을 추적할 수 있을 것이다. 이때는 Mapper 패키지만을 대상으로 TRACE를 설정하는 것이 좋을 것이다. 다른 것까지 TRACE 단계로 볼 필요는 없기 때문이다. 물론 additivity = false 를 명시해야 하여 부모 로거(root)의 설정이 덮어씌워지지 않도록 해야 한다.
어펜더 항목은 로그 기록의 패턴 레이아웃을 지정하고 있다. 개발자가 직접 원하는 패턴을 기입해도 된다.
(어펜더와 관련한 인코딩 이슈는 포스팅 제일 아래에 정리했다.)
xml 파일로 레벨과 어펜더를 조정하기 때문에 로그 설정 수정이 필요하면 그냥 xml 파일만 수정하면 된다. 복잡하고 시간이 걸리는 빌드 과정이 전혀 필요없다!!
그리고 파일의 위치는 반드시 클래스패스에 둬야 한다. 아래는 공식 문서의 설명(링크)이다.
Once the file above is placed into the classpath as log4j2.xml you will get results identical to those listed above.
따라서 자신이 사용하는 프로젝트의 빌드 및 배포 과정을 잘 추적해서 클래스패스의 정확한 위치에 <log4j2.xml>이 배치될 수 있도록 해야 할 것이다. (그레이들은 war로 빌드할 때 [resources] 디렉토리에 xml파일을 배치하면 자동으로 클래스패스([classes])에 xml이 배포된다. 물론 상세 빌드는 다를 수 있으므로 꼭 확인해보자.)
xml 파일이 없으면 디폴트 값이 반영되어 동작 자체는 여전히 수행된다.
Log4j will provide a default configuration if it cannot locate a configuration file.
그러나 레벨과 어펜더를 조정하지 않고 디폴트대로 사용한다면.. 솔직히 log4j2를 굳이 사용해야 할 이유는 없다...!
디폴트 설정과 관련해서는 헷갈릴 수 있으니 주의해야 한다. 뭔 말이냐면, 내가 직접 작성한 xml 파일을 인식하지 못해 디폴트 값을 사용하고 있는데도 나는 xml이 적용되고 있다고 착각할 수 있기 때문이다. 예를 들어, 테스트 코드를 빌드할 때 테스트 코드의 클래스패스에 xml을 두지 않아 디폴트 로깅으로 실행되고 있는데도 눈치채지 못한 아픈 기억이 있다...;
3. slf4j란? (라이브러리 의존성)

그레이들의 경우, log4j2 사용 시 위와 같은 의존성을 추가해주면 된다. (메이븐도 거의 똑같다.)
여기서 slf4j implementation 이라는 항목이 있다. 실제로 slf4j와 같은 단어는 hikariCP 등, 전혀 다른 라이브러리 사용 시 가끔 콘솔에 출력되는 문구다. 이것은 자바 로깅 라이브러리들의 일관된 인터페이스 사양이라고 보면 된다.
즉, 자바의 각종 라이브러리들이 만약 내부적으로 로깅을 해야 한다면, 구체적인 구현 라이브러리말고 slf4j와 같은 인터페이스에만 의존하는 것이다. 이렇게 하면 라이브러리 사용자가 자신이 원하는 로깅 라이브러리를 마음대로 선택할 수 있게 된다. (물론 그 로깅 라이브러리는 slf4j를 구현한 라이브러리여야 할 것이다)
SLF4J API를 사용한 라이브러리가 있을 때, log4j 라이브러리를 추가하는 것으로도 자동으로 그 라이브러리는 log4j를 사용해 로깅을 한다. 이렇게 하면 전체 프로젝트에서 통일된 로깅 시스템을 자동으로 구축할 수 있다. 이 기술이 SLF4J Binding이다.
예를 들어, hikariCP는 내부적으로 SLF4J API를 사용해 로그를 기록하는 시스템을 구현하고 있다. 내가 hikariCP를 단독으로 사용하면 hikariCP는 자신만의 로그 시스템으로 로그 기록을 출력하게 되는데, 그래서 콘솔 화면을 보면 slf4j 단어가 눈에 띄는 것이다.
만약 여기서 내가 log4j 라이브러리를 추가하면 자동 바인딩이 되어 hikariCP는 자신의 로그를 개발자가 설정한 log4j 로그 방식대로 따르는 것이다!
※ 예시 - 마이바티스도 마찬가지로 동작한다!! → 링크
4. 롬복(lombok)과 함께 사용하기
필수는 아니지만 롬복으로 간단하게 어노테이션만으로 로그와 관련된 코드 작성을 생략할 수 있다. (롬복을 모른다면 여기!! 링크 )

원리는 극히 단순하다. private static final Logger log = LogManager.getLogger(TodoService.class); 이 부분을 롬복이 기록해주는 것에 불과하다.
하지만 이것만으로도 꽤 간략하고 깔끔한 코드가 완성된다! 자바 개발자가 롬복을 사용하는 이유다. 개발자의 눈에 보이는 코드는 오직 log.info() 같은 메소드만 있기 때문에 코드가 상당히 깔끔해진다.
다만 롬복과 관련해 주의해야 할 점은, 롬복이 어노테이션 프로세서를 통해 반드시 소스코드를 수정하는 과정을 거쳐야만 작동한다는 것이다. 즉, 어노테이션 프로세서가 롬복의 @Log4j2를 식별하지 못하면 Logger 코드가 생략될 것이고, 따라서 log.info()는 오류를 내뱉게 된다.
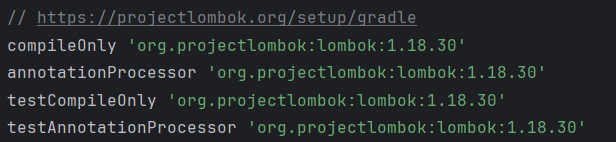
이런 문제를 test 코드를 작성하다가 오류를 만나곤 했다. 테스트 빌드 시에도 롬복을 작동시켜 반드시 소스코드를 컴파일하기 전에 필요한 코드들을 편집해야 제대로 컴파일될 것이다. 그레이들 빌드의 경우, 위와 같이 test에도 롬복이 어노테이션을 발견하고 수정할 수 있도록 프로세서에 등록해야 한다.
※ 한글 깨짐 문제
레이아웃에 한글을 사용하면 깨지는 문제가 발생한다. 한글 깨짐 문제는 언제나 인코딩 매칭 실패에서 온다. (설명: 링크) 아래는 log4j2 공식 홈페이지의 안내다.

<PatternLayout> 태그에 특별히 charset을 설정하지 않으면, 시스템의 디폴트 인코딩을 사용한다고 나와 있다. 윈도우의 시스템 인코딩은 CP949다. 따라서 자바 애플리케이션이 문자열 데이터를 log.info()의 인자로 넘겨주면, log4j2는 그걸 CP949로 변환해서 출력해버린다.
만약 콘솔을 UTF-8로 보고 있다면 문자열은 깨질 것이다. 보통 인텔리제이와 같은 IDE의 내장 콘솔 뷰어는 인코딩이 UTF-8로 설정된다. 따라서 아래와 같이 설정해야 한글이 깨지지 않을 것이다.

'IT 공부 > 자바와 웹 애플리케이션' 카테고리의 다른 글
| [톰캣] - 프로젝트 배포 시 라이브러리 위치 (0) | 2024.01.03 |
|---|---|
| [JUnit] - 아는 만큼만 정리.... (0) | 2024.01.03 |
| [lombok] - 롬복(lombok) 작동 원리 (어노테이션 프로세서) (0) | 2024.01.02 |
| [톰캣] - JavaEE(JakartaEE) 스펙 버전 지원 (0) | 2024.01.02 |
| [톰캣] - 웹 서버 기능을 구현하는 톰캣의 서블릿 매핑 (1) | 2024.01.02 |



